Last Updated on July 19, 2019
Generative Adversarial Networks, lub w skrócie GANs, są podejściem do modelowania generatywnego przy użyciu metod głębokiego uczenia się, takich jak sieci neuronowe convolutional.
Modelowanie generatywne jest zadaniem uczenia bez nadzoru w uczeniu maszynowym, które polega na automatycznym odkrywaniu i uczeniu się regularności lub wzorców w danych wejściowych w taki sposób, że model może być użyty do wygenerowania lub wyprowadzenia nowych przykładów, które prawdopodobnie mogły zostać wyciągnięte z oryginalnego zbioru danych.
GANs są sprytnym sposobem trenowania modelu generatywnego poprzez ujęcie problemu jako problemu uczenia nadzorowanego z dwoma pod-modelami: modelem generatora, który trenujemy do generowania nowych przykładów, oraz modelem dyskryminatora, który próbuje klasyfikować przykłady jako prawdziwe (z dziedziny) lub fałszywe (wygenerowane). Te dwa modele są trenowane razem w grze o sumie zerowej, przeciwstawnej, aż model dyskryminatora zostanie oszukany mniej więcej w połowie czasu, co oznacza, że model generatora generuje wiarygodne przykłady.
GAN są ekscytującą i szybko zmieniającą się dziedziną, spełniającą obietnicę modeli generatywnych w ich zdolności do generowania realistycznych przykładów w wielu dziedzinach problemowych, szczególnie w zadaniach tłumaczenia obrazów, takich jak tłumaczenie zdjęć lata na zimę lub dnia na noc, oraz w generowaniu fotorealistycznych zdjęć obiektów, scen i ludzi, o których nawet człowiek nie może powiedzieć, że są fałszywe.
W tym wpisie odkryjesz delikatne wprowadzenie do Generative Adversarial Networks, lub GANs.
Po przeczytaniu tego wpisu będziesz wiedział:
- Kontekst dla GANs, w tym uczenie nadzorowane vs. nienadzorowane oraz modelowanie dyskryminacyjne vs. generatywne.
- GAN-y są architekturą do automatycznego trenowania modelu generatywnego poprzez traktowanie problemu bez nadzoru jako nadzorowanego i używanie zarówno modelu generatywnego, jak i dyskryminacyjnego.
- GAN-y zapewniają ścieżkę do zaawansowanego rozszerzania danych specyficznych dla danej dziedziny oraz rozwiązanie problemów, które wymagają rozwiązania generatywnego, takich jak tłumaczenie obrazów.
Zacznij swój projekt dzięki mojej nowej książce Generative Adversarial Networks with Python, zawierającej tutoriale krok po kroku oraz pliki z kodem źródłowym Pythona dla wszystkich przykładów.
Zacznijmy.

Łagodne wprowadzenie do generatywnych sieci adwersarzowych (GAN)
Zdjęcie autorstwa Barneya Mossa, pewne prawa zastrzeżone.
- Przegląd
- What Are Generative Models?
- Supervised vs. Uczenie nienadzorowane
- Chcesz rozwijać GAN od podstaw?
- Modelowanie dyskryminacyjne vs. Modelowanie generatywne
- Przykłady modeli generatywnych
- Czym są Generative Adversarial Networks?
- Model generatora
- Model dyskryminatora
- GANs as a Two Player Game
- GANs and Convolutional Neural Networks
- Kondycjonalne GANs
- Why Generative Adversarial Networks?
- Further Reading
- Posts
- Books
- Papers
- Artykuły
- Podsumowanie
- Develop Generative Adversarial Networks Today!
- Develop Your GAN Models in Minutes
- Finally Bring GAN Models to your Vision Projects
Przegląd
Tutorial ten podzielony jest na trzy części; są to:
- Czym są modele generatywne?
- Czym są generatywne sieci adwersarzowe?
- Why Generative Adversarial Networks?
What Are Generative Models?
W tej części omówimy ideę modeli generatywnych, przechodząc do paradygmatów uczenia nadzorowanego i nienadzorowanego oraz modelowania dyskryminacyjnego i generatywnego.
Supervised vs. Uczenie nienadzorowane
Typowy problem uczenia maszynowego polega na użyciu modelu do przewidywania, np. modelowanie predykcyjne.
Wymaga to zbioru danych treningowych, który jest używany do trenowania modelu, składającego się z wielu przykładów, zwanych próbkami, każdy ze zmiennymi wejściowymi (X) i etykietami klasy wyjściowej (y). Model jest trenowany poprzez pokazywanie przykładów danych wejściowych, przewidywanie danych wyjściowych i korygowanie modelu, aby dane wyjściowe były bardziej zbliżone do oczekiwanych danych wyjściowych.
W podejściu do uczenia predykcyjnego lub nadzorowanego, celem jest nauczenie się mapowania od danych wejściowych x do danych wyjściowych y, biorąc pod uwagę etykietowany zestaw par danych wejściowych i wyjściowych…
– Strona 2, Machine Learning: A Probabilistic Perspective, 2012.
Ta korekta modelu jest ogólnie określana jako nadzorowana forma uczenia, lub uczenie nadzorowane.
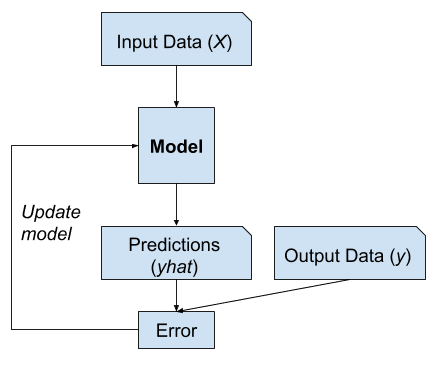
Przykłady uczenia nadzorowanego
Przykłady problemów uczenia nadzorowanego obejmują klasyfikację i regresję, a przykłady algorytmów uczenia nadzorowanego obejmują regresję logistyczną i las losowy.
Istnieje inny paradygmat uczenia, w którym model otrzymuje tylko zmienne wejściowe (X), a problem nie ma żadnych zmiennych wyjściowych (y).
Model jest konstruowany przez wyodrębnienie lub podsumowanie wzorców w danych wejściowych. Nie ma żadnej korekty modelu, ponieważ model niczego nie przewiduje.
Drugim głównym typem uczenia maszynowego jest podejście opisowe lub uczenie bez nadzoru. Tutaj mamy tylko dane wejściowe, a celem jest znalezienie „interesujących wzorców” w danych. Jest to znacznie mniej dobrze zdefiniowany problem, ponieważ nie mówi się nam, jakiego rodzaju wzorców mamy szukać, i nie ma oczywistej metryki błędu do wykorzystania (w przeciwieństwie do uczenia nadzorowanego, gdzie możemy porównać nasze przewidywanie y dla danego x z wartością obserwowaną).
– Strona 2, Machine Learning: A Probabilistic Perspective, 2012.
Ten brak korekty jest ogólnie określany jako nienadzorowana forma uczenia, lub uczenie nienadzorowane.
Przykłady uczenia nienadzorowanego
Przykłady problemów uczenia nienadzorowanego obejmują klasteryzację i modelowanie generatywne, a przykłady algorytmów uczenia nienadzorowanego to K-means i Generative Adversarial Networks.
Chcesz rozwijać GAN od podstaw?
Weź udział w moim darmowym 7-dniowym kursie e-mailowym (z przykładowym kodem).
Kliknij, aby się zapisać i otrzymać darmowy PDF Ebook z wersją kursu.
Ściągnij swój DARMOWY mini-kurs
Modelowanie dyskryminacyjne vs. Modelowanie generatywne
W uczeniu nadzorowanym możemy być zainteresowani stworzeniem modelu przewidującego etykietę klasy na podstawie przykładowych zmiennych wejściowych.
Takie zadanie modelowania predykcyjnego nazywamy klasyfikacją.
Klasyfikacja jest również tradycyjnie nazywana modelowaniem dyskryminacyjnym.
… używamy danych treningowych do znalezienia funkcji dyskryminacyjnej f(x), która odwzorowuje każdy x bezpośrednio na etykietę klasy, łącząc w ten sposób etapy wnioskowania i podejmowania decyzji w jeden problem uczenia się.
— Page 44, Pattern Recognition and Machine Learning, 2006.
This is because a model must discriminate examples of input variables across classes; it must choose or make a decision as to what class a given example belongs.
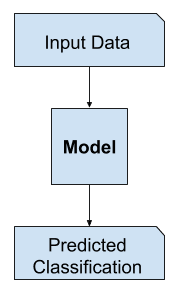
Example of Discriminative Modeling
Alternately, unsupervised models that summarize the distribution of input variables may be able to be used to create or generate new examples in the input distribution.
As such, these types of models are referred to as generative models.
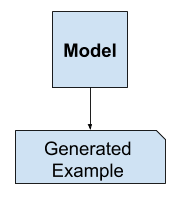
Example of Generative Modeling
For example, a single variable may have a known data distribution, such as a Gaussian distribution, or bell shape. Model generatywny może być w stanie wystarczająco podsumować ten rozkład danych, a następnie zostać wykorzystany do generowania nowych zmiennych, które wiarygodnie pasują do rozkładu zmiennej wejściowej.
Podejścia, które jawnie lub niejawnie modelują rozkład danych wejściowych, jak również wyjściowych, są znane jako modele generatywne, ponieważ poprzez próbkowanie z nich możliwe jest generowanie syntetycznych punktów danych w przestrzeni wejściowej.
– Strona 43, Pattern Recognition and Machine Learning, 2006.
W rzeczywistości, naprawdę dobry model generatywny może być w stanie wygenerować nowe przykłady, które są nie tylko wiarygodne, ale nieodróżnialne od rzeczywistych przykładów z domeny problemu.
Przykłady modeli generatywnych
Naive Bayes jest przykładem modelu generatywnego, który jest częściej używany jako model dyskryminacyjny.
Na przykład, Naive Bayes działa poprzez podsumowanie rozkładu prawdopodobieństwa każdej zmiennej wejściowej i klasy wyjściowej. Kiedy dokonywane jest przewidywanie, prawdopodobieństwo dla każdego możliwego wyniku jest obliczane dla każdej zmiennej, niezależne prawdopodobieństwa są łączone, a najbardziej prawdopodobny wynik jest przewidywany. Używane odwrotnie, rozkłady prawdopodobieństwa dla każdej zmiennej mogą być próbkowane w celu wygenerowania nowych prawdopodobnych (niezależnych) wartości cech.
Inne przykłady modeli generatywnych obejmują Latent Dirichlet Allocation, lub LDA, i Gaussian Mixture Model, lub GMM.
Metody głębokiego uczenia mogą być używane jako modele generatywne. Dwa popularne przykłady to Restricted Boltzmann Machine, czyli RBM, oraz Deep Belief Network, czyli DBN.
Dwa nowoczesne przykłady algorytmów głębokiego uczenia modeli generatywnych to Variational Autoencoder, czyli VAE, oraz Generative Adversarial Network, czyli GAN.
Czym są Generative Adversarial Networks?
Generative Adversarial Networks, lub GANs, są modelem generatywnym opartym na głębokim uczeniu.
Bardziej ogólnie, GANs są architekturą modelu do szkolenia modelu generatywnego, i najczęściej używa się modeli głębokiego uczenia w tej architekturze.
Architektura GAN została po raz pierwszy opisana w pracy z 2014 roku autorstwa Iana Goodfellow, et al. zatytułowanej „Generative Adversarial Networks.”
Standaryzowane podejście nazwane Deep Convolutional Generative Adversarial Networks, lub DCGAN, które doprowadziło do bardziej stabilnych modeli, zostało później sformalizowane przez Alec Radford, et al. w pracy z 2015 roku zatytułowanej „Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks”.
Większość dzisiejszych GAN-ów jest przynajmniej luźno oparta na architekturze DCGAN …
– NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
Architektura modelu GAN obejmuje dwa submodele: model generatora do generowania nowych przykładów i model dyskryminatora do klasyfikowania, czy wygenerowane przykłady są prawdziwe, z domeny, czy fałszywe, wygenerowane przez model generatora.
- Generator. Model służący do generowania nowych wiarygodnych przykładów z domeny problemu.
- Dyskryminator. Model, który jest używany do klasyfikacji przykładów jako prawdziwe (z domeny) lub fałszywe (wygenerowane).
Generatywne sieci przeciwstawne są oparte na teoretycznym scenariuszu gry, w którym sieć generatora musi konkurować z przeciwnikiem. Sieć generatora bezpośrednio produkuje próbki. Jej adwersarz, sieć dyskryminatora, próbuje odróżnić próbki wylosowane z danych treningowych od próbek wylosowanych z generatora.
– Strona 699, Deep Learning, 2016.
Model generatora
Model generatora przyjmuje wektor losowy o stałej długości jako dane wejściowe i generuje próbkę w domenie.
Wektor jest losowany z losowo z rozkładu gaussowskiego, a wektor jest używany do zasiania procesu generatywnego. Po treningu punkty w tej wielowymiarowej przestrzeni wektorowej będą odpowiadały punktom w domenie problemu, tworząc skompresowaną reprezentację rozkładu danych.
Ta przestrzeń wektorowa jest określana jako przestrzeń ukryta lub przestrzeń wektorowa złożona ze zmiennych ukrytych. Zmienne utajone, lub zmienne ukryte, to takie zmienne, które są ważne dla danej dziedziny, ale nie są bezpośrednio obserwowalne.
Zmienna utajona to zmienna losowa, której nie możemy bezpośrednio obserwować.
– Strona 67, Deep Learning, 2016.
Często odnosimy się do zmiennych utajonych, lub przestrzeni utajonej, jako projekcji lub kompresji rozkładu danych. To znaczy, przestrzeń latentna zapewnia kompresję lub wysokopoziomowe koncepcje obserwowanych surowych danych, takich jak rozkład danych wejściowych. W przypadku GAN, model generatora stosuje znaczenie do punktów w wybranej przestrzeni ukrytej, tak że nowe punkty wyciągnięte z przestrzeni ukrytej mogą być dostarczone do modelu generatora jako dane wejściowe i użyte do wygenerowania nowych i różnych przykładów wyjściowych.
Maszynowe modele uczące się mogą uczyć się statystycznej przestrzeni ukrytej obrazów, muzyki i historii, a następnie mogą próbkować z tej przestrzeni, tworząc nowe dzieła sztuki o cechach podobnych do tych, które model widział w swoich danych treningowych.
– Strona 270, Deep Learning with Python, 2017.
Po treningu model generatora jest zachowywany i wykorzystywany do generowania nowych próbek.
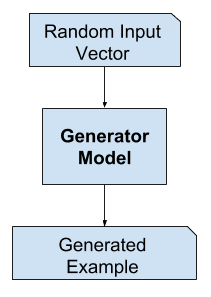
Przykład modelu generatora GAN
Model dyskryminatora
Model dyskryminatora przyjmuje jako dane wejściowe przykład z domeny (prawdziwy lub wygenerowany) i przewiduje binarną etykietę klasy prawdziwy lub fałszywy (wygenerowany).
Prawdziwy przykład pochodzi z zestawu danych treningowych. Wygenerowane przykłady są wyprowadzane przez model generatora.
Dyskryminator jest normalnym (i dobrze rozumianym) modelem klasyfikacyjnym.
Po procesie szkolenia model dyskryminatora jest odrzucany, ponieważ interesuje nas generator.
Niekiedy generator może być ponownie użyty, ponieważ nauczył się efektywnie ekstrahować cechy z przykładów w domenie problemu. Niektóre lub wszystkie warstwy ekstrakcji cech mogą być użyte w aplikacjach uczenia transferowego z wykorzystaniem tych samych lub podobnych danych wejściowych.
Proponujemy, że jednym ze sposobów budowania dobrych reprezentacji obrazów jest szkolenie Generative Adversarial Networks (GANs), a następnie ponowne wykorzystanie części sieci generatora i dyskryminatora jako ekstraktorów cech do zadań nadzorowanych
– Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
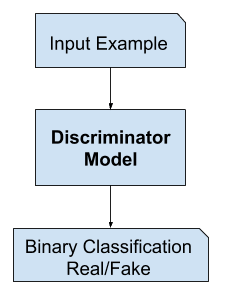
Przykład modelu dyskryminacyjnego GAN
GANs as a Two Player Game
Modelowanie generatywne jest problemem uczenia nienadzorowanego, jak to omówiliśmy w poprzedniej sekcji, chociaż sprytną właściwością architektury GAN jest to, że trening modelu generatywnego jest traktowany jako problem uczenia nadzorowanego.
Dwa modele, generator i dyskryminator, są trenowane razem. Generator generuje partię próbek, a te, wraz z prawdziwymi przykładami z dziedziny, są dostarczane do dyskryminatora i klasyfikowane jako prawdziwe lub fałszywe.
Dyskryminator jest następnie aktualizowany w celu uzyskania lepszych wyników w rozróżnianiu prawdziwych i fałszywych próbek w następnej rundzie, a co ważne, generator jest aktualizowany w oparciu o to, jak dobrze, lub nie, wygenerowane próbki oszukały dyskryminator.
Możemy myśleć o generatorze jak o fałszerzu, który próbuje stworzyć fałszywe pieniądze, a o dyskryminatorze jak o policji, która próbuje dopuścić legalne pieniądze i złapać fałszywe. Aby odnieść sukces w tej grze, fałszerz musi nauczyć się tworzyć pieniądze, które są nieodróżnialne od prawdziwych pieniędzy, a sieć generatora musi nauczyć się tworzyć próbki, które są wylosowane z tego samego rozkładu co dane treningowe.
– NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
W ten sposób dwa modele konkurują ze sobą, są adwersarzami w sensie teorii gier i grają w grę o sumie zerowej.
Ponieważ ramy GAN mogą być naturalnie analizowane za pomocą narzędzi teorii gier, nazywamy GAN-y „adwersarskimi”.
– NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
W tym przypadku suma zerowa oznacza, że gdy dyskryminator z powodzeniem identyfikuje prawdziwe i fałszywe próbki, jest nagradzany lub nie jest potrzebna żadna zmiana parametrów modelu, podczas gdy generator jest karany dużymi aktualizacjami parametrów modelu.
Alternatywnie, kiedy generator oszukuje dyskryminator, jest on nagradzany lub nie jest potrzebna żadna zmiana w parametrach modelu, ale dyskryminator jest karany i jego parametry modelu są aktualizowane.
Na granicy, generator generuje doskonałe repliki z domeny wejściowej za każdym razem, a dyskryminator nie może odróżnić i przewiduje „niepewność” (np. 50% dla prawdziwych i fałszywych) w każdym przypadku. To jest tylko przykład wyidealizowanego przypadku; nie musimy dojść do tego punktu, aby dojść do użytecznego modelu generatora.
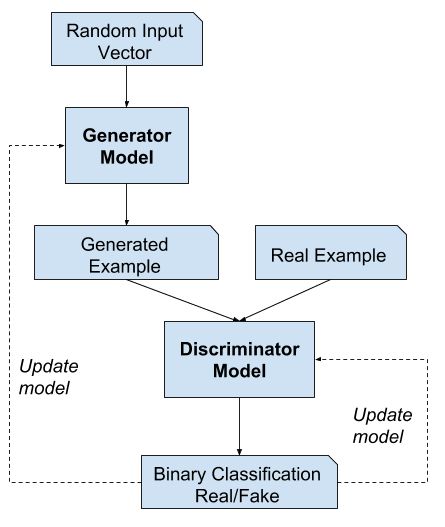
Przykład architektury generatywnego modelu sieci adwersarzowej
przenosi dyskryminator do próby nauczenia się poprawnego klasyfikowania próbek jako prawdziwe lub fałszywe. Równocześnie generator próbuje oszukać klasyfikator, aby uwierzył, że jego próbki są prawdziwe. Przy zbieżności, próbki generatora są nie do odróżnienia od prawdziwych danych, a dyskryminator wszędzie daje wynik 1/2. Dyskryminator może być wtedy odrzucony.
– Strona 700, Deep Learning, 2016.
GANs and Convolutional Neural Networks
GANs typically work with image data and use Convolutional Neural Networks, or CNNs, as the generator and discriminator models.
Powodem tego może być zarówno fakt, że pierwszy opis tej techniki powstał w dziedzinie wizji komputerowej i wykorzystywał CNN i dane obrazowe, jak i niezwykły postęp, jaki dokonał się w ostatnich latach dzięki wykorzystaniu CNN w celu osiągnięcia najnowocześniejszych rezultatów w szeregu zadań wizji komputerowej, takich jak wykrywanie obiektów i rozpoznawanie twarzy.
Modelowanie danych obrazowych oznacza, że przestrzeń ukryta, wejście do generatora, stanowi skompresowaną reprezentację zbioru obrazów lub fotografii używanych do trenowania modelu. Oznacza to również, że generator generuje nowe obrazy lub fotografie, dostarczając dane wyjściowe, które mogą być łatwo przeglądane i oceniane przez twórców lub użytkowników modelu.
To może być ten fakt ponad innymi, zdolność do wizualnej oceny jakości wygenerowanego wyjścia, która doprowadziła zarówno do skupienia się na aplikacjach widzenia komputerowego z CNNs, jak i na ogromnych skokach w możliwościach GANs w porównaniu z innymi modelami generatywnymi, opartymi na głębokim uczeniu lub w inny sposób.
Kondycjonalne GANs
Ważnym rozszerzeniem GAN jest ich użycie do warunkowego generowania wyjścia.
Model generatywny może być trenowany do generowania nowych przykładów z domeny wejściowej, gdzie dane wejściowe, wektor losowy z przestrzeni ukrytej, są dostarczane (uwarunkowane) przez pewne dodatkowe dane wejściowe.
Dodatkowymi danymi wejściowymi mogą być wartości klasowe, takie jak mężczyzna lub kobieta w przypadku generowania zdjęć ludzi, lub cyfra w przypadku generowania obrazów cyfr pisma odręcznego.
Generatywne sieci przeciwstawne można rozszerzyć do modelu warunkowego, jeśli zarówno generator, jak i dyskryminator są uwarunkowane pewną dodatkową informacją y. y może być dowolną informacją pomocniczą, taką jak etykiety klas lub dane z innych modalności. Warunkowanie możemy przeprowadzić podając y zarówno do dyskryminatora, jak i generatora jako dodatkową warstwę wejściową.
– Conditional Generative Adversarial Nets, 2014.
Dyskryminator również jest uwarunkowany, co oznacza, że otrzymuje zarówno obraz wejściowy, który jest prawdziwy lub fałszywy, jak i dodatkowe dane wejściowe. W przypadku wejścia warunkowego typu etykiety klasyfikacyjnej, dyskryminator spodziewałby się, że dane wejściowe będą tej klasy, co z kolei nauczyłoby generator generowania przykładów tej klasy w celu oszukania dyskryminatora.
W ten sposób warunkowy GAN może być użyty do generowania przykładów z domeny danego typu.
Podejmując krok dalej, modele GAN mogą być uwarunkowane na przykładzie z domeny, takim jak obraz. Pozwala to na takie zastosowania GAN-ów jak tłumaczenie tekstu na obraz, czy obrazu na obraz. Pozwala to na niektóre z bardziej imponujących zastosowań GAN, takich jak przenoszenie stylu, koloryzacja zdjęć, przekształcanie zdjęć z lata na zimę lub z dnia na noc, i tak dalej.
W przypadku warunkowych GAN do tłumaczenia obrazu na obraz, takich jak przekształcanie dnia na noc, dyskryminator jest dostarczany przykłady rzeczywistych i wygenerowanych zdjęć nocnych, jak również (uwarunkowane na) rzeczywistych zdjęć dziennych jako wejście. Generatorowi dostarczany jest wektor losowy z przestrzeni ukrytej, jak również (uwarunkowany na) rzeczywiste zdjęcia dzienne jako dane wejściowe.
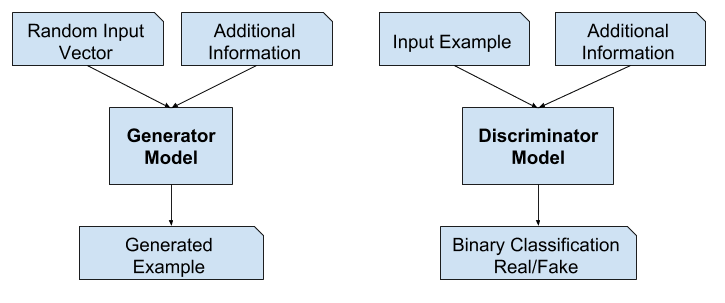
Przykład architektury modelu sieci adwersarzowej warunkowo generatywnej
Why Generative Adversarial Networks?
Jednym z wielu znaczących postępów w stosowaniu metod głębokiego uczenia w dziedzinach takich jak widzenie komputerowe jest technika zwana rozszerzaniem danych.
Rozszerzanie danych skutkuje lepszymi wynikami modeli, zarówno zwiększając umiejętności modelu, jak i zapewniając efekt regularyzacji, zmniejszając błąd generalizacji. Działa ona poprzez tworzenie nowych, sztucznych, ale wiarygodnych przykładów z dziedziny problemu wejściowego, na którym trenowany jest model.
W przypadku danych obrazowych, techniki te są prymitywne i polegają na przycinaniu, przerzucaniu, powiększaniu i innych prostych przekształceniach istniejących obrazów w zbiorze danych treningowych.
Sukcesywne modelowanie generatywne zapewnia alternatywne i potencjalnie bardziej specyficzne dla danej dziedziny podejście do powiększania danych. W rzeczywistości, augmentacja danych jest uproszczoną wersją modelowania generatywnego, chociaż rzadko jest opisywana w ten sposób.
… powiększanie próby o dane ukryte (nieobserwowalne). Nazywa się to powiększaniem danych. W innych problemach dane utajone to rzeczywiste dane, które powinny być obserwowane, ale ich brakuje.
– Strona 276, The Elements of Statistical Learning, 2016.
W złożonych domenach lub domenach z ograniczoną ilością danych, modelowanie generatywne zapewnia ścieżkę w kierunku większej ilości szkoleń dla modelowania. GAN-y odniosły duży sukces w tym przypadku użycia w domenach takich jak głębokie uczenie wzmacniające.
Istnieje wiele powodów badawczych, dla których GAN-y są interesujące, ważne i wymagają dalszych badań. Ian Goodfellow nakreślił szereg z nich w swoim keynote z konferencji w 2016 roku i powiązanym raporcie technicznym zatytułowanym „NIPS 2016 Tutorial: Generative Adversarial Networks.”
Wśród tych powodów podkreśla on udaną zdolność GAN-ów do modelowania danych wielowymiarowych, obsługi brakujących danych oraz zdolność GAN-ów do dostarczania wielomodalnych danych wyjściowych lub wielu prawdopodobnych odpowiedzi.
Prawdopodobnie najbardziej przekonującym zastosowaniem GAN-ów jest warunkowe GAN-owanie zadań, które wymagają generowania nowych przykładów. Tutaj Goodfellow wskazuje trzy główne przykłady:
- Superrozdzielczość obrazu. Zdolność do generowania wersji obrazów wejściowych o wysokiej rozdzielczości.
- Tworzenie sztuki. Zdolność do tworzenia nowych, artystycznych obrazów, szkiców, malarstwa i innych.
- Tłumaczenie obrazów. Zdolność do tłumaczenia zdjęć w różnych dziedzinach, takich jak dzień do nocy, lato do zimy, i więcej.
Prawdopodobnie najbardziej przekonującym powodem, że GAN są szeroko badane, rozwijane i używane jest ich sukces. GAN były w stanie wygenerować zdjęcia tak realistyczne, że ludzie nie są w stanie powiedzieć, że są to obiekty, sceny i ludzie, którzy nie istnieją w prawdziwym życiu.
Piękne nie jest wystarczającym przymiotnikiem dla ich możliwości i sukcesu.

Przykład progresji możliwości GAN-ów od 2014 do 2017 roku. Zaczerpnięte z książki The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation, 2018.
Further Reading
Ta sekcja zawiera więcej zasobów na ten temat, jeśli szukasz pogłębienia.
Posts
- Best Resources for Getting Started With Generative Adversarial Networks (GANs)
- 18 Impressive Applications of Generative Adversarial Networks (GANs)
Books
- Chapter 20. Deep Generative Models, Deep Learning, 2016.
- Chapter 8. Generative Deep Learning, Deep Learning with Python, 2017.
- Machine Learning: A Probabilistic Perspective, 2012.
- Pattern Recognition and Machine Learning, 2006.
- The Elements of Statistical Learning, 2016.
Papers
- Generative Adversarial Networks, 2014.
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
- NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
- Conditional Generative Adversarial Nets, 2014.
- The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation, 2018.
Artykuły
- Model generatywny, Wikipedia.
- Latent Variable, Wikipedia.
- Generative Adversarial Network, Wikipedia.
Podsumowanie
W tym poście, odkryłeś delikatne wprowadzenie do Generative Adversarial Networks, lub GANs.
Szczegółowo, dowiedziałeś się:
- Kontekst dla GANs, w tym nadzorowane vs. Uczenie nienadzorowane oraz modelowanie dyskryminacyjne i generatywne.
- GAN-y są architekturą do automatycznego trenowania modelu generatywnego poprzez traktowanie problemu nienadzorowanego jako nadzorowanego i używanie zarówno modelu generatywnego, jak i dyskryminacyjnego.
- GAN-y zapewniają ścieżkę do zaawansowanego rozszerzania danych specyficznych dla danej dziedziny oraz rozwiązanie problemów, które wymagają rozwiązania generatywnego, takich jak tłumaczenie obrazów.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Generative Adversarial Networks Today!

Develop Your GAN Models in Minutes
…with just a few lines of python code
Discover how in my new Ebook:
Generative Adversarial Networks with Python
It provides self-study tutorials and end-to-end projects on:
DCGAN, conditional GANs, image translation, Pix2Pix, CycleGAN
and much more…
Finally Bring GAN Models to your Vision Projects
Skip the Academics. Just Results.See What’s Inside