
- Podsumowanie
- Obecna topologia sieci korporacyjnych
- Potencjalne korzyści
- Potencjalne pułapki
- Co oznacza pojęcie „edge computing”?
- Jak CDN-y przetarły szlak
- Tendencja w kierunku decentralizacji
- Cele poziomu usług
- Sieć warstwowa
- Zlokalizowanie krawędzi na mapie
- „Krawędź technologii operacyjnej”
- Trójdzielna sieć Della
- Wyłaniająca się „chmura brzegowa”
- Dowiedz się więcej – Z CBS Interactive Network
- Elsewhere
Podsumowanie
Na brzegu każdej sieci istnieją możliwości umieszczenia serwerów, procesorów i macierzy pamięci masowej danych jak najbliżej osób, które mogą je najlepiej wykorzystać. Tam, gdzie można zmniejszyć odległość, ponieważ prędkość elektronów jest zasadniczo stała, minimalizuje się opóźnienia. Sieć zaprojektowana do korzystania z brzegu wykorzystuje ten minimalny dystans, aby przyspieszyć usługi i wygenerować wartość.
W nowoczesnej sieci komunikacyjnej zaprojektowanej do użytku na brzegu – na przykład sieci bezprzewodowej 5G – istnieją dwie możliwe strategie działania:
- Strumienie danych, audio i wideo mogą być odbierane szybciej i z mniejszymi przerwami (najlepiej żadnymi), gdy serwery są oddzielone od użytkowników minimalną liczbą pośrednich punktów routingu, czyli „hopów”. Sieci dostarczania treści (CDN) od dostawców takich jak Akamai, Cloudflare i NTT Communications i są zbudowane wokół tej strategii.
- Aplikacje mogą być przyspieszone, gdy ich procesory znajdują się bliżej miejsca, gdzie dane są gromadzone. Jest to szczególnie prawdziwe w przypadku aplikacji dla logistyki i produkcji na dużą skalę, a także dla Internetu rzeczy (IoT), gdzie czujniki lub urządzenia zbierające dane są liczne i bardzo rozproszone.
Zależnie od aplikacji, gdy zastosowana jest jedna lub obie strategie brzegowe, serwery te mogą faktycznie znaleźć się na jednym lub drugim końcu sieci. Ponieważ Internet nie jest zbudowany jak stara sieć telefoniczna, „bliżej” w sensie celowości routingu niekoniecznie jest bliżej w sensie odległości geograficznej. A w zależności od tego, z iloma różnymi typami dostawców usług zakontraktowała się Twoja organizacja – dostawcami aplikacji w chmurze publicznej (SaaS), dostawcami platformy aplikacji (PaaS), dostawcami dzierżawionej infrastruktury (IaaS), sieciami dostarczania treści – może istnieć wiele obszarów nieruchomości IT walczących o bycie „brzegiem” w danym momencie.

Wewnątrz szafy mikrocentrum danych Schneider Electric
Scott Fulton
Obecna topologia sieci korporacyjnych
Są trzy miejsca, w których większość przedsiębiorstw ma tendencję do wdrażania i zarządzania własnymi aplikacjami i usługami:
- Na miejscu, gdzie centra danych mieszczą wiele szaf z serwerami, gdzie są wyposażone w zasoby potrzebne do ich zasilania i chłodzenia oraz gdzie istnieje dedykowana łączność z zasobami zewnętrznymi
- Obiekty kolokacyjne, gdzie sprzęt klienta jest umieszczony w pełni zarządzanym budynku, w którym zasilanie, chłodzenie i łączność są dostarczane jako usługi
- Dostawcy usług w chmurze, gdzie infrastruktura klienta może być do pewnego stopnia zwirtualizowana, a usługi i aplikacje są dostarczane na zasadzie per-use, umożliwiając rozliczanie operacji jako wydatków operacyjnych, a nie nakładów kapitałowych
Architekci edge computing chcieliby dodać swój projekt jako czwartą kategorię do tej listy: taką, która wykorzystuje przenośność mniejszych, skonteneryzowanych obiektów z mniejszymi, bardziej modularnymi serwerami, aby zmniejszyć odległości między punktem przetwarzania a punktem konsumpcji funkcjonalności w sieci. Jeśli ich plany się sprawdzą, dążą do osiągnięcia następujących celów:
Potencjalne korzyści
- Minimalne opóźnienia. Problem z usługami cloud computing polega na tym, że są one powolne, szczególnie w przypadku obciążeń wykorzystujących sztuczną inteligencję. To w zasadzie dyskwalifikuje chmurę do poważnego wykorzystania w deterministycznych aplikacjach, takich jak prognozowanie rynków papierów wartościowych w czasie rzeczywistym, pilotowanie autonomicznych pojazdów i wyznaczanie tras w ruchu transportowym. Procesory umieszczone w małych centrach danych, bliżej miejsca, gdzie będą wykorzystywane ich procesy, mogą otworzyć nowe rynki dla usług obliczeniowych, których dostawcy chmur nie byli w stanie do tej pory zaadresować. W scenariuszu IoT, gdzie klastry samodzielnych urządzeń zbierających dane są szeroko rozproszone, posiadanie procesorów bliżej nawet podgrup lub klastrów tych urządzeń mogłoby znacznie poprawić czas przetwarzania, czyniąc analitykę w czasie rzeczywistym wykonalną na znacznie bardziej ziarnistym poziomie.
- Uproszczona konserwacja. Dla przedsiębiorstwa, które nie ma problemów z wysłaniem floty ciężarówek lub pojazdów serwisowych do lokalizacji w terenie, mikrocentra danych (µDC) zostały zaprojektowane z myślą o maksymalnej dostępności, modułowości i rozsądnym stopniu przenośności. Są to kompaktowe obudowy, niektóre na tyle małe, że mieszczą się w tylnej części pickupa, które mogą pomieścić tylko tyle serwerów, ile potrzeba do obsługi funkcji krytycznych w czasie, które można rozmieścić bliżej ich użytkowników. Można sobie wyobrazić, że w przypadku budynku, który obecnie mieści, zasila i chłodzi swoje zasoby centrum danych w piwnicy, zastąpienie całej operacji trzema lub czterema µDC gdzieś na parkingu może faktycznie stanowić ulepszenie.
- Tańsze chłodzenie. W przypadku dużych kompleksów centrów danych miesięczny koszt energii elektrycznej zużywanej do chłodzenia może z łatwością przekroczyć koszt energii elektrycznej zużywanej do przetwarzania. Stosunek tych dwóch wielkości nazywany jest efektywnością wykorzystania energii (PUE). Niekiedy jest to podstawowa miara wydajności centrum danych (choć w ostatnich latach badania wykazały, że coraz mniej operatorów IT wie, co ten wskaźnik właściwie oznacza). Teoretycznie, chłodzenie i klimatyzowanie kilku mniejszych centrów danych może kosztować firmę mniej niż jednego dużego. Ponadto, ze względu na osobliwe sposoby rozliczania w niektórych obszarach usług energetycznych, koszt jednego kilowata może spaść we wszystkich przypadkach dla tych samych szaf serwerowych umieszczonych w kilku małych obiektach zamiast w jednym dużym. W białej księdze z 2017 r. opublikowanej przez Schneider Electric oceniono wszystkie większe i mniejsze koszty związane z budową tradycyjnych i mikrocentrów danych. Podczas gdy przedsiębiorstwo mogłoby ponieść nieco poniżej 7 mln USD nakładów kapitałowych na budowę tradycyjnego obiektu o mocy 1 MW, wydałoby nieco ponad 4 mln USD, aby ułatwić 200 obiektów o mocy 5 KW.
- Świadomość klimatyczna. Idea dystrybucji mocy obliczeniowej do klientów na szerszym obszarze geograficznym, w przeciwieństwie do centralizacji tej mocy w ogromnych, hiperskalowych obiektach i polegania na łączach światłowodowych o wysokiej przepustowości, zawsze była ekologicznie atrakcyjna. Wczesny marketing dla edge computing opiera się na zdroworozsądkowym wrażeniu słuchaczy, że mniejsze obiekty zużywają mniej energii, nawet zbiorowo. Ale jury wciąż nie wie, czy to rzeczywiście prawda. Badanie przeprowadzone w 2018 r. przez naukowców z Uniwersytetu Technicznego w Koszycach na Słowacji , wykorzystujące symulowane wdrożenia obliczeń brzegowych w scenariuszu IoT, wykazało, że efektywność energetyczna krawędzi zależy prawie całkowicie od dokładności i wydajności prowadzonych tam obliczeń. Koszty ogólne ponoszone przez nieefektywne obliczenia, jak stwierdzili, byłyby w rzeczywistości powiększone przez złe programowanie.
Jeśli wszystko to brzmi jak zbyt złożony system, aby był wykonalny, należy pamiętać, że w swojej obecnej formie, model publicznej chmury obliczeniowej może nie być zrównoważony w dłuższej perspektywie. Model ten miałby abonentów nadal pchać aplikacji, strumieni danych i strumieni treści przez rury połączone z kompleksów hiperskalowych, których obszary usług obejmują całe stany, prowincje i kraje – system, że dostawcy bezprzewodowych usług głosowych nigdy nie odważyłby się próbować.
Potencjalne pułapki
Niemniej jednak, świat obliczeniowy całkowicie przebudowany w modelu edge computing jest tak fantastyczny – i tak odległy – jak świat transportu, który odzwyczaił się całkowicie od paliw ropopochodnych. W najbliższym czasie, model obliczeń brzegowych napotka kilka istotnych przeszkód, z których kilka nie będzie łatwych do pokonania:
- Zdalna dostępność zasilania trójfazowego. Serwery zdolne do świadczenia zdalnych usług w chmurze dla klientów komercyjnych, niezależnie od tego, gdzie się znajdują, potrzebują procesorów o dużej mocy i danych w pamięci, aby umożliwić multi-tenancy. Prawdopodobnie bez wyjątku będą wymagały dostępu do prądu trójfazowego o wysokim napięciu. Jest to niezwykle trudne, jeśli nie niemożliwe, do osiągnięcia w stosunkowo odległych, wiejskich lokalizacjach. (Zwykły prąd przemienny 120 V jest jednofazowy). Stacje bazowe Telco nigdy nie wymagały takiego poziomu zasilania, a jeśli nie mają być wykorzystywane do użytku komercyjnego przez wielu najemców, to i tak mogą nie potrzebować zasilania trójfazowego. Jedynym powodem, dla którego należałoby doposażyć system energetyczny, byłaby opłacalność obliczeń brzegowych. Jednak w przypadku szeroko rozpowszechnionych aplikacji Internetu Rzeczy, takich jak testy zdalnych monitorów serca w Mississippi, brak wystarczającej infrastruktury zasilania mógłby skończyć się ponownym podziałem na tych, którzy „mają” i tych, którzy „nie mają”. Aby przejście na 5G było opłacalne, telkomy muszą czerpać dodatkowe przychody z przetwarzania brzegowego. Tym, co sprawiło, że pomysł powiązania ewolucji edge computing z 5G był pomysł, że funkcje komercyjne i operacyjne mogą współistnieć na tych samych serwerach – koncepcja wprowadzona przez Central Office Re-architected as a Datacenter (CORD) (pierwotnie „Re-imagined”), której jedna z form jest obecnie uważana za kluczowy czynnik ułatwiający 5G Wireless. Problem w tym, że może nawet nie być legalne, aby operacje fundamentalne dla sieci telekomunikacyjnej współistniały z funkcjami klienta w tych samych systemach – odpowiedzi zależą od tego, czy prawodawcy są w stanie zrozumieć nową definicję „systemów”. Do tego dnia (jeśli kiedykolwiek nadejdzie), 3GPP (organizacja branżowa zarządzająca standardami 5G) przyjęła koncepcję zwaną network slicing, która jest sposobem na podzielenie serwerów sieci telco na serwery wirtualne na bardzo niskim poziomie, z dużo większą separacją niż w typowym środowisku wirtualizacji, np. w VMware. Można sobie wyobrazić, że wycinek sieci skierowany do klienta mógłby być wdrożony na brzegu sieci telco, obsługując ograniczoną liczbę klientów. Jednak niektóre większe przedsiębiorstwa wolałyby przejąć odpowiedzialność za własne wycinki sieci, nawet jeśli oznaczałoby to wdrożenie ich we własnych obiektach – przeniesienie brzegu sieci na ich teren – niż inwestować w nowy system, którego propozycja wartości opiera się w dużej mierze na nadziejach.
- Operatorzy telekomunikacyjni broniący swoich macierzystych terytoriów przed lokalnymi wyłomami. Jeśli radiowa sieć dostępowa 5G (RAN) i połączone z nią kable światłowodowe mają być wykorzystane do świadczenia komercyjnych usług dla klientów, musi istnieć jakiś rodzaj bramy, aby odseparować ruch klientów prywatnych od ruchu operatorów telekomunikacyjnych. Architektura takiej bramy już istnieje i została formalnie przyjęta przez 3GPP. Nazywa się to local breakout, i jest także częścią oficjalnej deklaracji ETSI dotyczącej wielodostępu brzegowego (multi-access edge computing, MEC). Więc technicznie rzecz biorąc, ten problem został rozwiązany. Problem w tym, że niektórzy operatorzy telekomunikacyjni mogą mieć interes w zapobieganiu przekierowania ruchu klientów z drogi, którą normalnie by podążali: do ich własnych centrów danych. Dzisiejsza topologia sieci internetowej ma trzy poziomy: Dostawcy usług warstwy 1 współpracują tylko między sobą, podczas gdy dostawcy usług internetowych warstwy 2 są zazwyczaj nastawieni na klienta. Trzecia warstwa pozwala na istnienie mniejszych, regionalnych dostawców usług internetowych na bardziej lokalnym poziomie. Edge computing na skalę globalną może stać się katalizatorem dla usług w stylu chmury publicznej, oferowanych przez dostawców usług internetowych na poziomie lokalnym, być może poprzez rodzaj „sieci sklepów”. Ale to przy założeniu, że operatorzy telekomunikacyjni, którzy zarządzają Tier-2, są skłonni po prostu pozwolić przychodzący ruch sieciowy być podzielony na trzeci poziom, umożliwiając konkurencję na rynku, który mogliby bardzo łatwo po prostu rościć sobie prawo do siebie.
Jeśli lokalizacja, lokalizacja, lokalizacja ma ponownie znaczenie dla przedsiębiorstw, to cały rynek komputerów dla przedsiębiorstw może być odwrócony na jego ucho. Hiperskalowa, scentralizowana, żądna mocy natura centrów danych w chmurze może w końcu zadziałać przeciwko nim, ponieważ mniejsze, bardziej zwinne, bardziej opłacalne modele operacyjne wyrastają – jak mniszek lekarski, jeśli wszystko pójdzie zgodnie z planem – w szerzej rozproszonych lokalizacjach.
„Uważam, że zainteresowanie wdrożeniami brzegowymi”, zauważył Kurt Marko, dyrektor firmy Marko Insights zajmującej się analizą technologii, w notatce dla ZDNet, „jest przede wszystkim napędzane przez potrzebę przetwarzania ogromnych ilości danych generowanych przez 'inteligentne’ urządzenia, czujniki i użytkowników – szczególnie mobilnych/bezprzewodowych. Rzeczywiście, prędkości przesyłu danych i przepustowość sieci 5G, wraz z rosnącym wykorzystaniem danych przez klientów, będą wymagać, aby mobilne stacje bazowe stały się mini centrami danych.”
Co oznacza pojęcie „edge computing”?
W każdej sieci telekomunikacyjnej, krawędź to najdalszy zasięg jej urządzeń i usług w kierunku klientów. W kontekście edge computing, krawędź jest miejscem na planecie, gdzie serwery mogą dostarczyć funkcjonalność do klientów w najbardziej odpowiedni sposób.
Jak CDN-y przetarły szlak

Diagram relacji między centrami danych a urządzeniami Internetu Rzeczy, przedstawiony przez Industrial Internet Consortium.
W odniesieniu do Internetu, obliczanie lub przetwarzanie jest prowadzone przez serwery – komponenty zwykle reprezentowane przez kształt (na przykład chmurę) w pobliżu centrum lub punktu centralnego diagramu sieci. Dane są zbierane z urządzeń na krawędziach tego diagramu i ciągnięte do centrum w celu przetworzenia. Przetworzone dane, jak ropa z rafinerii, są pompowane z powrotem w kierunku krawędzi w celu dostarczenia. Sieci CDN przyspieszają ten proces, działając jako „stacje benzynowe” dla użytkowników znajdujących się w ich pobliżu. Typowy cykl życia produktu dla usług sieciowych obejmuje ten proces „obiegu”, w którym dane są efektywnie wydobywane, wysyłane, rafinowane i ponownie wysyłane. I, jak w każdym procesie, który wymaga logistyki, transport wymaga czasu.
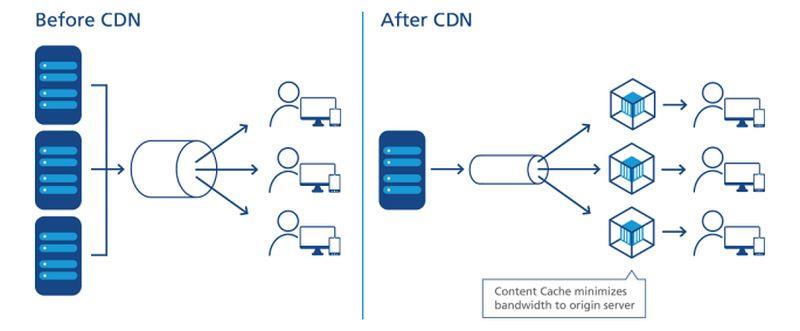
Dokładne, obrazowe umiejscowienie serwerów CDN w procesie dostarczania danych.
NTT Communictions
Co ważne, to czy CDN zawsze znajduje się w centrum diagramu, zależy od tego, czyj diagram oglądamy. Jeśli dostawca CDN sporządził go, nie może być duży „CDN” chmura w centrum, z sieci przedsiębiorstw wzdłuż krawędzi jednej strony, a urządzenia użytkownika sprzętu wzdłuż innych krawędzi. Wyjątkiem jest firma NTT, której uproszczony, ale dokładniejszy diagram pokazuje serwery CDN wstrzykujące się pomiędzy punkt dostępu do danych a użytkowników. Z perspektywy producentów danych lub treści, w przeciwieństwie do podmiotów dostarczających, sieci CDN znajdują się na końcu łańcucha dostaw – stanowią kolejny, przedostatni krok w przypadku danych, zanim otrzyma je użytkownik.
W ciągu ostatniej dekady główni dostawcy CDN zaczęli wprowadzać usługi obliczeniowe, które rezydują w punkcie dostawy. Wyobraźmy sobie, że stacja benzynowa może być swoją własną rafinerią, a zrozumiemy ideę. Propozycja wartości dla tej usługi zależy od tego, że CDN są postrzegane nie w centrum, ale na krawędzi. Dzięki temu niektóre dane mogą ominąć potrzebę transportu, tylko po to, aby zostać przetworzone i przetransportowane z powrotem.
Tendencja w kierunku decentralizacji
Jeśli CDN-y nie udowodniły jeszcze skuteczności edge computing jako usługi, to przynajmniej pokazały jej wartość jako biznesu: Przedsiębiorstwa będą płacić premie za przetwarzanie niektórych danych, zanim dotrą one do centrum lub „rdzenia” sieci.
„Byliśmy na dość długi okres centralizacji”, wyjaśnił Matt Baker, starszy wiceprezes Dell Technologies ds. strategii i planowania, podczas konferencji prasowej w lutym ubiegłego roku. „A ponieważ świat poszukuje możliwości dostarczania coraz bardziej cyfrowych doświadczeń w czasie rzeczywistym poprzez swoje inicjatywy cyfrowej transformacji, zdolność do utrzymania tego wysoce scentralizowanego podejścia do IT zaczyna się dość mocno łamać”.
Edge computing został okrzyknięty jednym z lukratywnych, nowych rynków, które stały się wykonalne dzięki technologii bezprzewodowej 5G. Aby globalne przejście z 4G na 5G było ekonomicznie wykonalne dla wielu firm telekomunikacyjnych, nowa generacja musi otworzyć nowe, możliwe do wykorzystania kanały przychodów. 5G wymaga ogromnej, nowej sieci (jak na ironię) przewodowych, światłowodowych połączeń, aby zapewnić nadajnikom i stacjom bazowym natychmiastowy dostęp do danych cyfrowych (backhaul). W rezultacie pojawia się szansa dla nowej klasy dostawców usług obliczeniowych, aby wdrożyć wiele µDC w sąsiedztwie wież radiowej sieci dostępowej (RAN), być może obok lub w tym samym budynku co stacje bazowe firm telekomunikacyjnych. Te centra danych mogłyby wspólnie oferować usługi chmury obliczeniowej wybranym klientom po stawkach konkurencyjnych i funkcjach porównywalnych z dostawcami chmury hiperskalowej, takimi jak Amazon, Microsoft Azure i Google Cloud Platform.
Idealnie, być może po dekadzie lub tak ewolucji, edge computing przyniesie szybkie usługi do klientów tak blisko, jak ich najbliższe stacje bazowe sieci bezprzewodowych. Potrzebowalibyśmy ogromnych rur światłowodowych, aby zapewnić niezbędny backhaul, ale przychody z usług edge computing mogłyby sfinansować ich budowę, umożliwiając opłacalność.
Cele poziomu usług
W ostatecznej analizie (jeśli w ogóle jakakolwiek analiza kiedykolwiek była ostateczna), sukces lub porażka centrów danych na brzegach sieci będzie określona przez ich zdolność do spełnienia celów poziomu usług (SLO). Są to oczekiwania klientów płacących za usługi, skodyfikowane w ich umowach serwisowych. Inżynierowie mają metryki, których używają do rejestrowania i analizowania wydajności komponentów sieciowych. Klienci mają tendencję do unikania tych metryk, wybierając zamiast tego faworyzowanie obserwowalnej wydajności swoich aplikacji. Jeśli wdrożenie brzegowe nie jest zauważalnie szybsze niż wdrożenie hiperskalowe, to brzeg jako koncepcja może umrzeć w powijakach.
„Na czym nam zależy? Czas reakcji aplikacji” – wyjaśnił Tom Gillis, wiceprezes VMware ds. sieci i bezpieczeństwa, podczas niedawnej konferencji firmy. „Jeśli możemy scharakteryzować sposób, w jaki aplikacja odpowiada, i przyjrzeć się poszczególnym komponentom pracującym nad dostarczeniem tej odpowiedzi aplikacji, możemy faktycznie zacząć tworzyć tę samoregenerującą się infrastrukturę”.
Zmniejszenie opóźnień i poprawa szybkości przetwarzania (z nowszymi serwerami dedykowanymi do znacznie mniejszej ilości zadań ilościowo) powinny grać na korzyść SLO. Niektórzy wskazują również, że szerokie rozmieszczenie zasobów na danym obszarze przyczynia się do redundancji usług, a nawet ciągłości działania – które, przynajmniej do czasu pandemii, były postrzegane jako zdarzenia jedno- lub dwudniowe, po których następowały okresy odbudowy.
Będą jednak czynniki równoważące, z których najważniejszy ma związek z konserwacją i utrzymaniem. Typowy obiekt centrum danych warstwy 2 może być utrzymywany w warunkach awaryjnych (takich jak pandemia) przez zaledwie dwie osoby na miejscu, z personelem pomocniczym poza nim. Tymczasem µDC jest zaprojektowane tak, aby funkcjonować bez konieczności ciągłego zatrudniania personelu. Jego wbudowane funkcje monitorowania nieustannie wysyłają dane telemetryczne do centralnego węzła, który teoretycznie może znajdować się w chmurze publicznej. Tak długo, jak µDC spełnia swoje SLO, nie musi być osobiście obsługiwane.
W tym miejscu opłacalność modelu edge computing musi być jeszcze dokładnie przetestowana. W przypadku typowego kontraktu z dostawcą centrum danych, SLO jest często mierzony na podstawie tego, jak szybko personel dostawcy jest w stanie rozwiązać nierozwiązany problem. Zazwyczaj czas rozwiązywania problemów może pozostać na niskim poziomie, jeśli personel nie musi dojeżdżać do punktów awarii ciężarówkami. Jeśli model wdrożenia brzegowego ma być konkurencyjny w stosunku do modelu wdrożenia kolokacyjnego, jego zautomatyzowane możliwości naprawcze muszą być zadziwiająco dobre.
Sieć warstwowa
Dostawcy pamięci masowych, hosty aplikacji chmurowych, dostawcy usług Internetu rzeczy (IoT), producenci serwerów, firmy zarządzające inwestycjami w nieruchomości (REIT) i producenci wstępnie zmontowanych obudów serwerowych – wszyscy oni torują ekspresowe drogi między swoimi klientami a tym, co dla każdego z nich zapowiada się na krawędź.
To, czego wszyscy oni tak naprawdę szukają, to przewaga konkurencyjna. Idea przewagi daje nową nadzieję na perspektywę usług premium – solidny, uzasadniony powód, dla którego pewne klasy usług są droższe od innych. Jeśli przeczytałeś lub usłyszałeś gdzie indziej, że krawędź może ostatecznie wchłonąć całą chmurę, możesz zrozumieć teraz, że nie miałoby to większego sensu. Gdyby wszystko było premium, nic nie byłoby premium.
„Edge computing jest najwyraźniej idealnym rozwiązaniem technologicznym, a inwestorzy venture capital twierdzą, że będzie to rynek technologiczny wart wiele miliardów dolarów”, zauważył Kevin Brown, CTO i starszy wiceprezes ds. innowacji w firmie Schneider Electric, dostawcy sprzętu dla centrów danych i producenta mikro obudów centrów danych. „Nikt tak naprawdę nie wie, czym on jest”.

Kevin Brown z firmy Schneider Electric: „Nikt tak naprawdę nie wie, co to jest.”
Brown przyznał, że edge computing może przypisać swoją historię pionierskim sieciom CDN, takim jak Akamai. Mimo to, kontynuował, „masz wszystkie te różne warstwy – HPE ma swoją wersję, Cisco ma swoją. . . Nie byliśmy w stanie zrozumieć żadnej z nich. Nasze spojrzenie na krawędź jest naprawdę bardzo uproszczone. W przyszłości na świecie będą istniały trzy rodzaje centrów danych, o które naprawdę trzeba się martwić.”
Obraz, który narysował Brown, podczas wydarzenia prasowego w siedzibie firmy w Massachusetts w lutym 2019 roku, jest ponownie pojawiającym się poglądem na trójwarstwowy Internet i jest podzielany przez rosnącą liczbę firm technologicznych. W tradycyjnym modelu dwuwarstwowym węzły Tier-1 są ograniczone do peeringu z innymi węzłami Tier-1, podczas gdy węzły Tier-2 zajmują się dystrybucją danych na poziomie regionalnym. Od początku istnienia Internetu istniało oznaczenie Tier-3 – dla dostępu na znacznie bardziej lokalnym poziomie. (Porównaj to ze schematem komórkowej radiowej sieci dostępowej, w której dystrybucja ruchu jest jednowarstwowa).
„Pierwszy punkt, w którym podłączasz się do sieci, jest tak naprawdę tym, co uważamy za lokalną krawędź”, wyjaśnia Brown. Odwzorowując dzisiejszą technologię, można by znaleźć jedno z dzisiejszych urządzeń brzegowych w dowolnym serwerze wciśniętym w prowizoryczny stojak w szafie z okablowaniem.
„Dla naszych celów,” kontynuował, „uważamy, że to jest miejsce, gdzie toczy się akcja.”
„Krawędź, przez lata, były hotele Tier-1 operatorskie, takie jak Equinix i CoreSite. One w zasadzie nawarstwiałyby jedną sieć łączącą się z drugą, i to było uważane za krawędź” – wyjaśnił Wen Temitim, CTO dostawcy usług infrastruktury brzegowej StackPath. „Ale to, co widzimy, ze wszystkimi różnymi zmianami w użytkowaniu opartymi na zachowaniu konsumentów, a także z COVID-19 i pracą w domu, to nowa i głębsza krawędź, która staje się bardziej istotna dla dostawców usług”.
Zlokalizowanie krawędzi na mapie
Edge computing jest wysiłkiem mającym na celu przywrócenie jakości usług (QoS) do dyskusji na temat architektury centrów danych i usług, ponieważ przedsiębiorstwa decydują nie tylko o tym, kto będzie dostarczał ich usługi, ale również gdzie.
„Krawędź technologii operacyjnej”
Producent sprzętu dla centrów danych HPE – główny inwestor w edge computing – wierzy, że następny gigantyczny skok w infrastrukturze operacyjnej będzie koordynowany i prowadzony przez pracowników i wykonawców, którzy mogą nie mieć zbyt wiele, jeśli w ogóle, osobistych inwestycji lub szkoleń w zakresie sprzętu i infrastruktury – ludzi, którzy do tej pory byli w dużej mierze odpowiedzialni za konserwację, utrzymanie i wsparcie oprogramowania. Jej firma nazywa zakres obowiązków tej klasy pracowników technologią operacyjną (OT). W przeciwieństwie do tych, którzy dostrzegają zbieżność IT i operacji w takiej czy innej formie „DevOps”, HPE dostrzega trzy klasy klientów korzystających z technologii brzegowych. Nie tylko każda z tych klas, w jej opinii, utrzyma swoją własną platformę obliczeniową, ale geografia tych platform będzie oddzielona od siebie, a nie zbieżna, jak to przedstawia diagram HPE.

Tutaj, istnieją trzy odrębne klasy klientów, z których każdy HPE przydzielił swój własny segment krawędzi w ogóle. Klasa OT odnosi się tutaj do klientów bardziej skłonnych do przypisania menedżerów do edge computing, którzy mają mniej bezpośrednie doświadczenie z IT, głównie dlatego, że ich główne produkty nie są informacje lub komunikacja sama. Tej klasie przypisuje się „krawędź OT”. Gdy przedsiębiorstwo ma więcej bezpośrednich inwestycji w informacje jako branżę lub jest w dużym stopniu zależne od informacji jako składnika swojej działalności, HPE przypisuje mu „krawędź IT”. Pomiędzy nimi, dla tych przedsiębiorstw, które są rozproszone geograficznie i zależą od logistyki (gdzie informacja ma bardziej logiczny komponent), a tym samym od Internetu rzeczy, HPE nadaje im „IoT edge”.
Trójdzielna sieć Della

W 2017 roku firma Dell Technologies po raz pierwszy zaproponowała swoją trójwarstwową topologię dla całego rynku obliczeniowego, dzieląc go na „rdzeń”, „chmurę” i „krawędź”. Jak wskazuje ten slajd z wczesnej prezentacji Della, podział ten wydawał się radykalnie prosty, przynajmniej na początku: Zasoby IT każdego klienta można podzielić odpowiednio na 1) to, co jest jego własnością i jest utrzymywane przez jego własny personel; 2) to, co przekazuje dostawcy usług i zatrudnia go do utrzymania; oraz 3) to, co rozprowadza poza swoimi macierzystymi obiektami w terenie, aby było utrzymywane przez specjalistów operacyjnych (którzy mogą, ale nie muszą być outsourcowani).
W prezentacji z listopada 2018 r. dla Linux Foundation’s Embedded Linux Conference Europe, CTO for IoT and Edge Computing Jason Shepherd przedstawił ten prosty przypadek: Tak wiele sieciowych urządzeń i sprzętów jest planowanych do IoT, że centralizacja zarządzania nimi będzie technologicznie niemożliwa, także jeśli zaciągniemy się do chmury publicznej.
„Moja żona i ja mamy trzy koty”, powiedział Shepherd swoim słuchaczom. „Mamy większe możliwości przechowywania danych w naszych telefonach, więc mogliśmy wysyłać filmy o kotach tam i z powrotem.

„Filmy z kotami wyjaśniają potrzebę przetwarzania brzegowego,” kontynuował. „Jeśli opublikuję jeden z moich filmów online, i zacznie on zdobywać hity, muszę buforować go na większej ilości serwerów, daleko w chmurze. Jeśli to się rozchodzi wirusowo, wtedy muszę przenieść tę zawartość tak blisko abonentów, jak to tylko możliwe. Jako firma telekomunikacyjna, Netflix czy jakakolwiek inna, najbliżej mogę być na krawędzi chmury – na dole moich wież komórkowych, tych kluczowych punktów w Internecie. To jest właśnie koncepcja MEC, Multi-access Edge Computing – przybliżanie treści do abonentów. Cóż, teraz, jeśli mam miliardy podłączonych rozmówców kota tam, mam całkowicie odwrócił paradygmat, a zamiast rzeczy próbuje ciągnąć w dół, mam wszystkie te urządzenia próbuje pchać się w górę. To sprawia, że musisz przesunąć obliczenia jeszcze bardziej w dół.”
Wyłaniająca się „chmura brzegowa”
Od czasu światowej premiery przestraszonego kociaka Shepherda, koncepcja krawędzi Della nieco stwardniała, od zniuansowanego montażu warstw do bardziej podstawowej etyki decentralizacji.
„Widzimy krawędź jako naprawdę zdefiniowaną niekoniecznie przez konkretne miejsce lub konkretną technologię”, powiedział Matt Baker z firmy Dell w lutym ubiegłego roku. „Zamiast tego, jest to komplikacja w istniejącym rozmieszczeniu IT, ponieważ coraz bardziej decentralizujemy nasze środowiska IT, okazuje się, że umieszczamy rozwiązania infrastruktury IT, oprogramowanie, itp. w coraz bardziej ograniczonych środowiskach. Centrum danych jest środowiskiem w dużej mierze pozbawionym ograniczeń; można je zbudować zgodnie ze specyfikacją, którą się chce, można je odpowiednio chłodzić, jest w nim dużo miejsca. Ale ponieważ umieszczamy coraz więcej technologii w otaczającym nas świecie, aby ułatwić dostarczanie tych cyfrowych doświadczeń w czasie rzeczywistym, znajdujemy się w miejscach, które są w pewien sposób zagrożone.”
Sieci kampusowe, powiedział Baker, zawierają sprzęt, który ma tendencję do bycia zakurzonym i brudnym, oprócz posiadania łączności o niskiej przepustowości. Środowiska telekomunikacyjne często zawierają szafy o bardzo małej głębokości, wymagające bardzo dużej gęstości zaludnienia procesorów. A w najdalszych miejscach na mapie, istnieje niedobór wykwalifikowanej siły roboczej IT, „co kładzie większy nacisk na zdolność do zarządzania wysoce rozproszonych środowisk w hands-off, unmanned .”
Niemniej jednak, na coraz większej liczbie klientów spoczywa obowiązek przetwarzania danych bliżej punktu, w którym są one po raz pierwszy oceniane lub tworzone, argumentował. To stawia lokalizację „krawędzi”, około 2020 roku, w dowolnym punkcie na mapie, gdzie można znaleźć dane, z braku lepszego określenia, zapalające się.
StackPath’s Temitim uważa, że tym punktem jest wyłaniająca się koncepcja zwana chmurą brzegową – efektywnie wirtualny zbiór wielu wdrożeń brzegowych w jednej platformie. Platforma ta będzie sprzedawana na początku do wielokanałowych dystrybutorów wideo (MVPD, zwykle zasiedziałych firm kablowych, ale także niektórych operatorów telekomunikacyjnych), którzy chcą posiadać własne sieci dystrybucji i obniżyć koszty w dłuższej perspektywie. Jednak jako dodatkowe źródło przychodów, dostawcy ci mogliby następnie oferować usługi podobne do chmury publicznej, takie jak aplikacje SaaS lub nawet hosting serwerów wirtualnych, w imieniu klientów komercyjnych.
Taki rynek „chmur brzegowych” mógłby bezpośrednio konkurować z centrami danych średniej wielkości Tier-2 i Tier-3 na świecie. Ponieważ operatorzy tych obiektów są zazwyczaj klientami premium operatorów telekomunikacyjnych w swoich regionach, mogą oni postrzegać chmurę brzegową jako konkurencyjne zagrożenie dla swoich własnych planów związanych z 5G Wireless. To naprawdę jest, jak to ujął jeden z dostawców infrastruktury brzegowej, „fizyczne zagarnięcie ziemi”. A zagarnianie tak naprawdę dopiero się zaczęło.
Dowiedz się więcej – Z CBS Interactive Network
- Jak edge computing może odmienić i zrewitalizować nieruchomości komercyjne Larry Dignan, Between the Lines
- To wyścig do krawędzi i koniec chmury obliczeniowej jaką znamy Scott M. Fulton, III, Scale
- Make edge computing a key investment for 2020 by Forrester Research
Elsewhere
- The Data Center That’s a Coffee Table by Scott M. Fulton, III, Data Center Knowledge
- Dell Joins AT&T to Move Edge Data Centers Wherever They Should Be by Scott M. Fulton, III, Data Center Knowledge
- Challenges and Solutions in Edge Computing: The Future by Pam Baker, Linux.com