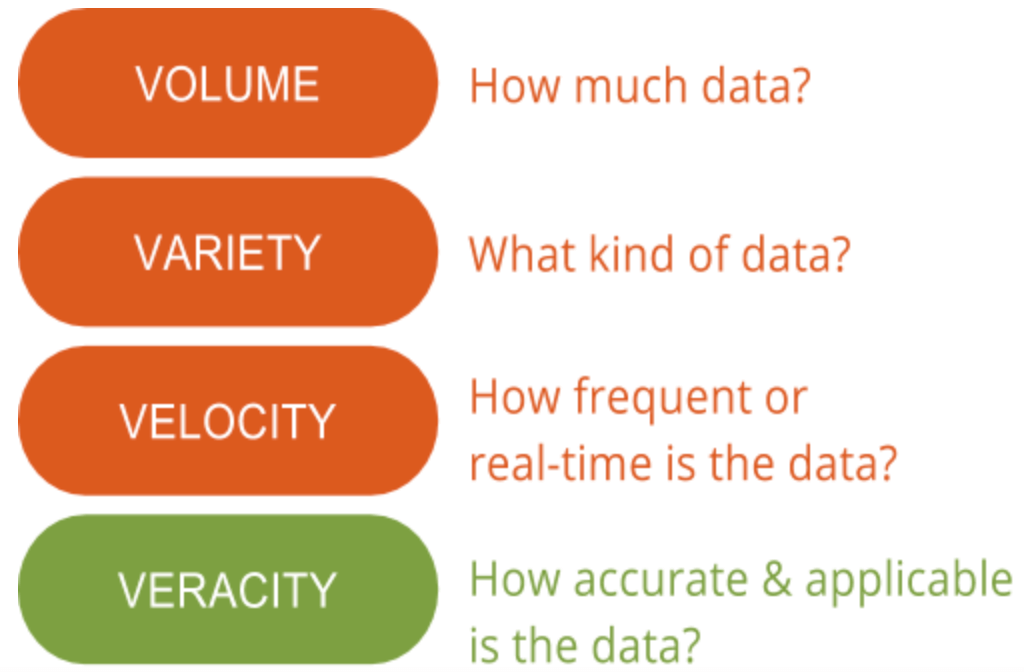
W GutCheck dużo mówimy o 4 V Big Data: volume, variety, velocity i veracity. Jest jednak jedno „V”, którego znaczenie podkreślamy ponad wszystkie inne – prawdziwość danych. Prawdziwość danych to obszar, który wciąż ma potencjał do poprawy i stanowi największe wyzwanie, jeśli chodzi o big data. Przy tak dużej ilości dostępnych danych, zapewnienie ich istotności i wysokiej jakości stanowi różnicę między tymi, którzy z powodzeniem wykorzystują big data, a tymi, którzy mają trudności z ich zrozumieniem.
 Zrozumienie znaczenia prawdziwości danych jest pierwszym krokiem w odróżnianiu sygnału od szumu, jeśli chodzi o big data. Innymi słowy, prawdziwość danych pomaga przefiltrować to, co jest ważne, a co nie, a w efekcie końcowym generuje głębsze zrozumienie danych i sposobów ich kontekstualizacji w celu podjęcia działań.
Zrozumienie znaczenia prawdziwości danych jest pierwszym krokiem w odróżnianiu sygnału od szumu, jeśli chodzi o big data. Innymi słowy, prawdziwość danych pomaga przefiltrować to, co jest ważne, a co nie, a w efekcie końcowym generuje głębsze zrozumienie danych i sposobów ich kontekstualizacji w celu podjęcia działań.
Co to jest prawdziwość danych?
Prawdziwość danych, ogólnie rzecz biorąc, to stopień dokładności lub prawdziwości zestawu danych. W kontekście big data, nabiera to jednak nieco większego znaczenia. Dokładniej, jeśli chodzi o dokładność big data, nie chodzi tylko o jakość samych danych, ale o to, na ile wiarygodne jest źródło danych, ich rodzaj i przetwarzanie. Usuwanie błędów, nieprawidłowości lub niespójności, duplikacji i zmienności to tylko kilka aspektów, które wpływają na poprawę dokładności big data.
Niestety, czasami zmienność nie jest pod naszą kontrolą. Zmienność, czasami określana jako kolejne „V” big data, to tempo zmian i czas życia danych. Przykładem danych o wysokiej zmienności są media społecznościowe, gdzie nastroje i trendy zmieniają się szybko i często. Mniej zmienne dane przypominają trendy pogodowe, które zmieniają się rzadziej i są łatwiejsze do przewidzenia i śledzenia.
Druga strona prawdziwości danych wiąże się z zapewnieniem, że metoda przetwarzania rzeczywistych danych ma sens w oparciu o potrzeby biznesowe, a dane wyjściowe są adekwatne do celów. Oczywiście, jest to szczególnie ważne w przypadku łączenia pierwotnych badań rynkowych z big data. Interpretacja big data we właściwy sposób zapewnia, że wyniki są istotne i możliwe do podjęcia działań. Ponadto, dostęp do big data oznacza, że można spędzić miesiące na sortowaniu informacji bez skupienia i bez metody identyfikowania, które punkty danych są istotne. W rezultacie, dane powinny być analizowane w odpowiednim czasie, co jest trudne w przypadku big data, w przeciwnym razie wnioski nie będą użyteczne.
Dlaczego to ważne
Big data jest wysoce złożona, a w rezultacie środki do jej zrozumienia i interpretacji są nadal w pełni skonceptualizowane. Podczas gdy wielu uważa, że uczenie maszynowe będzie miało duże zastosowanie w analizie big data, metody statystyczne są nadal potrzebne, aby zapewnić jakość danych i praktyczne zastosowanie big data dla badaczy rynku. Na przykład, nie ściągnąłbyś raportu branżowego z Internetu i nie użyłbyś go do podjęcia działań. Zamiast tego prawdopodobnie zweryfikowałbyś go lub wykorzystał do dodatkowych badań przed sformułowaniem własnych wniosków. Nie inaczej jest w przypadku big data; nie można przyjmować big data takimi, jakimi są, bez ich walidacji lub wyjaśnienia. Jednak w przeciwieństwie do większości praktyk badania rynku, big data nie ma silnych podstaw w statystyce.
Dlatego poświęciliśmy czas na zrozumienie platform zarządzania danymi i big data, aby kontynuować pionierskie metody, które integrują, agregują i interpretują dane z precyzją klasy badawczej, tak jak wypróbowane i prawdziwe metody, do których jesteśmy przyzwyczajeni. Część tych metod obejmuje indeksowanie i czyszczenie danych, a także wykorzystywanie danych pierwotnych w celu zapewnienia lepszego kontekstu i utrzymania prawdziwości spostrzeżeń.
Wiele organizacji nie jest w stanie poświęcić tyle czasu, ile potrzeba, aby naprawdę przekonać się, czy źródło big data i metoda jego przetwarzania zapewniają wysoki poziom prawdziwości. Współpraca z partnerem, który ma pojęcie o podstawach big data w badaniach rynku, może w tym pomóc. Aby dowiedzieć się, w jaki sposób nasz klient wykorzystał insighty oparte na ankietach i danych behawioralnych (big data), zapoznaj się z poniższym studium przypadku. Zobaczysz również, w jaki sposób udało się połączyć kropki i odblokować moc inteligencji odbiorców w celu stworzenia lepszej strategii segmentacji konsumentów.