
- Résumé exécutif
- La topologie actuelle des réseaux d’entreprise
- Avantages potentiels
- Ecueils potentiels
- Que signifie « edge computing » ?
- Comment les CDN ont ouvert la voie
- La tendance à la décentralisation
- Objectifs de niveau de service
- Le réseau hiérarchisé
- La localisation de la périphérie sur une carte
- La « technologie opérationnelle de pointe »
- Le réseau tripartite de Dell
- Le « edge cloud » émergent
- En savoir plus – Du réseau interactif CBS
- Ailleurs
Résumé exécutif
À la périphérie de tout réseau, il existe des opportunités pour positionner les serveurs, les processeurs et les matrices de stockage de données aussi près que possible de ceux qui peuvent en faire le meilleur usage. Là où vous pouvez réduire la distance, la vitesse des électrons étant essentiellement constante, vous minimisez la latence. Un réseau conçu pour être utilisé à la périphérie exploite cette distance minimale pour accélérer le service et générer de la valeur.
Dans un réseau de communication moderne conçu pour être utilisé à la périphérie – par exemple, un réseau sans fil 5G – deux stratégies possibles sont à l’œuvre :
- Les flux de données, audio et vidéo peuvent être reçus plus rapidement et avec moins de pauses (de préférence aucune) lorsque les serveurs sont séparés de leurs utilisateurs par un minimum de points de routage intermédiaires, ou « sauts ». Les réseaux de diffusion de contenu (CDN) de fournisseurs tels qu’Akamai, Cloudflare et NTT Communications et sont construits autour de cette stratégie.
- Les applications peuvent être accélérées lorsque leurs processeurs sont stationnés plus près du lieu de collecte des données. Cela est particulièrement vrai pour les applications de logistique et de fabrication à grande échelle, ainsi que pour l’Internet des objets (IoT), où les capteurs ou les dispositifs de collecte de données sont nombreux et fortement distribués.
Selon l’application, lorsque l’une ou l’autre ou les deux stratégies de périphérie sont employées, ces serveurs peuvent en fait se retrouver à une extrémité du réseau ou à l’autre. L’Internet n’étant pas construit comme l’ancien réseau téléphonique, « plus proche » en termes de rapidité de routage n’est pas nécessairement plus proche en distance géographique. Et selon le nombre de types différents de fournisseurs de services avec lesquels votre organisation a passé un contrat – fournisseurs d’applications de cloud public (SaaS), fournisseurs de plateformes d’apps (PaaS), fournisseurs d’infrastructures louées (IaaS), réseaux de diffusion de contenu – il peut y avoir plusieurs parcelles de biens immobiliers informatiques qui se disputent le titre de « bord » à tout moment.

Inside d’une armoire de micro data center Schneider Electric
Scott Fulton
La topologie actuelle des réseaux d’entreprise
Il existe trois endroits où la plupart des entreprises ont tendance à déployer et à gérer leurs propres applications et services :
- Sur site, où les centres de données abritent plusieurs racks de serveurs, où ils sont équipés des ressources nécessaires pour les alimenter et les refroidir, et où il y a une connectivité dédiée aux ressources extérieures
- Les installations de colocation, où l’équipement du client est hébergé dans un bâtiment entièrement géré où l’alimentation, le refroidissement, et la connectivité sont fournis en tant que services
- Fournisseurs de services en nuage, où l’infrastructure du client peut être virtualisée dans une certaine mesure, et où les services et les applications sont fournis sur la base de l’utilisation, ce qui permet de comptabiliser les opérations en tant que dépenses opérationnelles plutôt qu’en tant que dépenses d’investissement
Les architectes de l’informatique périphérique chercheraient à ajouter leur conception comme une quatrième catégorie à cette liste : celle qui exploite la portabilité d’installations plus petites et conteneurisées avec des serveurs plus petits et plus modulaires, afin de réduire les distances entre le point de traitement et le point de consommation de la fonctionnalité dans le réseau. Si leurs plans se concrétisent, ils cherchent à accomplir ce qui suit :
Avantages potentiels
- Latence minimale. Le problème des services de cloud computing aujourd’hui est qu’ils sont lents, en particulier pour les charges de travail basées sur l’intelligence artificielle. Cela disqualifie essentiellement le cloud pour une utilisation sérieuse dans les applications déterministes, telles que les prévisions en temps réel des marchés de valeurs mobilières, le pilotage des véhicules autonomes et l’acheminement du trafic de transport. Les processeurs stationnés dans de petits centres de données, plus proches de l’endroit où leurs processus seront utilisés, pourraient ouvrir de nouveaux marchés pour les services informatiques que les fournisseurs de cloud computing n’ont pas été en mesure d’aborder jusqu’à présent. Dans un scénario IoT, où des grappes d’appareils autonomes de collecte de données sont largement distribuées, le fait d’avoir des processeurs plus proches même des sous-groupes ou des grappes de ces appareils pourrait améliorer considérablement le temps de traitement, rendant l’analyse en temps réel réalisable à un niveau beaucoup plus granulaire.
- Maintenance simplifiée. Pour une entreprise qui n’a pas beaucoup de mal à envoyer une flotte de camions ou de véhicules de maintenance sur le terrain, les microcentres de données (µDC) sont conçus pour une accessibilité maximale, une modularité et un degré raisonnable de portabilité. Il s’agit d’enceintes compactes, dont certaines sont assez petites pour tenir à l’arrière d’une camionnette, qui peuvent accueillir juste assez de serveurs pour héberger des fonctions critiques, et qui peuvent être déployées plus près de leurs utilisateurs. Il est concevable que, pour un bâtiment qui abrite, alimente et refroidisse actuellement ses actifs de centre de données dans son sous-sol, le remplacement de toute cette opération par trois ou quatre µDC quelque part dans le parking pourrait en fait constituer une amélioration.
- Un refroidissement moins coûteux. Pour les grands complexes de centres de données, le coût mensuel de l’électricité utilisée pour le refroidissement peut facilement dépasser le coût de l’électricité utilisée pour le traitement. Le rapport entre les deux est appelé efficacité de l’utilisation de l’énergie (PUE). Il s’agit parfois de la mesure de base de l’efficacité d’un centre de données (bien que, ces dernières années, des enquêtes aient montré que les opérateurs informatiques sont moins nombreux à savoir ce que signifie réellement ce ratio). En théorie, il peut être moins coûteux pour une entreprise de refroidir et de conditionner plusieurs petits espaces de centre de données que d’en utiliser un seul grand. De plus, en raison de la manière particulière dont certaines zones de service d’électricité gèrent la facturation, le coût par kilowatt peut baisser de manière générale pour les mêmes racks de serveurs hébergés dans plusieurs petites installations plutôt que dans une grande. Un livre blanc publié en 2017 par Schneider Electric a évalué tous les coûts majeurs et mineurs associés à la construction de centres de données traditionnels et de microcentres. Alors qu’une entreprise pourrait encourir un peu moins de 7 millions de dollars en dépenses d’investissement pour la construction d’une installation traditionnelle de 1 MW, elle dépenserait un peu plus de 4 millions de dollars pour faciliter 200 installations de 5 KW.
- Conscience climatique. Il y a toujours eu un certain attrait écologique à l’idée de distribuer la puissance de calcul aux clients à travers une zone géographique plus large, par opposition à la centralisation de cette puissance dans des installations mammouths et hyperscale, et en s’appuyant sur des liens en fibre optique à large bande passante pour la connectivité. Les premiers efforts de marketing en faveur de l’informatique périphérique reposent sur l’impression de bon sens des auditeurs que les petites installations consomment moins d’énergie, même collectivement. Mais le jury ne sait toujours pas si c’est réellement vrai. Une étude réalisée en 2018 par des chercheurs de l’Université technique de Kosice, en Slovaquie , à l’aide de déploiements simulés d’edge computing dans un scénario IoT, a conclu que l’efficacité énergétique de l’edge dépend presque entièrement de la précision et de l’efficacité des calculs qui y sont effectués. Les frais généraux encourus par des calculs inefficaces, ont-ils constaté, seraient en fait amplifiés par une mauvaise programmation.
Si tout cela semble être un système trop complexe pour être réalisable, gardez à l’esprit que dans sa forme actuelle, le modèle de cloud computing public pourrait ne pas être viable à long terme. Ce modèle obligerait les abonnés à continuer de pousser des applications, des flux de données et des flux de contenu dans des tuyaux reliés à des complexes hyperscale dont les zones de service englobent des états, des provinces et des pays entiers – un système que les fournisseurs de voix sans fil n’auraient jamais osé tenter.
Ecueils potentiels
Néanmoins, un monde informatique entièrement refait selon le modèle de l’edge computing est à peu près aussi fantastique – et aussi éloigné – qu’un monde des transports qui se serait entièrement sevré des carburants pétroliers. À court terme, le modèle d’informatique de périphérie est confronté à des obstacles importants, dont plusieurs ne seront pas tout à fait faciles à surmonter :
- Disponibilité à distance d’une alimentation triphasée. Les serveurs capables de fournir des services à distance de type cloud à des clients commerciaux, quel que soit l’endroit où ils se trouvent, ont besoin de processeurs de grande puissance et de données en mémoire, pour permettre la multi-location. Probablement sans exception, ils devront avoir accès à une alimentation électrique triphasée à haute tension. C’est extrêmement difficile, voire impossible, à obtenir dans des endroits relativement éloignés et ruraux. (Le courant alternatif ordinaire de 120 V est monophasé.) Les stations de base des télécoms n’ont jamais eu besoin de ce niveau d’alimentation jusqu’à présent, et si elles ne sont pas destinées à être exploitées pour un usage commercial multi-locataires, elles n’auront peut-être jamais besoin d’une alimentation triphasée de toute façon. La seule raison de rénover le système d’alimentation serait si l’informatique de périphérie est viable. Mais pour les applications de l’Internet des objets largement distribuées, comme les essais de moniteurs cardiaques à distance du Mississippi, l’absence d’une infrastructure d’alimentation suffisante pourrait finir par diviser une fois de plus les « nantis » des « démunis ».
- Découpage des serveurs en tranches virtuelles protégées. Pour que la transition vers la 5G soit abordable, les télécoms doivent tirer des revenus supplémentaires de l’informatique de périphérie. Ce qui a fait naître l’idée de lier l’évolution de l’edge computing à la 5G, c’est l’idée que les fonctions commerciales et opérationnelles pourraient coexister sur les mêmes serveurs – un concept introduit par Central Office Re-architected as a Datacenter (CORD) (à l’origine « Re-imagined »), dont une forme est maintenant considérée comme un facilitateur clé de la 5G Wireless. Le problème, c’est qu’il n’est peut-être même pas légal que des opérations fondamentales pour le réseau de télécommunications cohabitent avec des fonctions clients sur les mêmes systèmes – les réponses dépendent de la capacité des législateurs à comprendre la nouvelle définition des « systèmes ». En attendant ce jour (s’il arrive un jour), la 3GPP (l’organisation industrielle qui régit les normes 5G) a adopté un concept appelé « network slicing », qui permet de découper les serveurs des réseaux de télécommunications en serveurs virtuels à un niveau très bas, avec une séparation beaucoup plus grande que dans un environnement de virtualisation typique de VMware, par exemple. Il est concevable qu’une tranche de réseau orientée client puisse être déployée à la périphérie des réseaux des opérateurs de télécommunications, pour desservir un nombre limité de clients. Cependant, certaines grandes entreprises préfèrent prendre en charge leurs propres tranches de réseau, même si cela implique de les déployer dans leurs propres installations – en déplaçant la périphérie dans leurs locaux – plutôt que d’investir dans un nouveau système dont la proposition de valeur repose en grande partie sur l’espoir.
- Les télécoms défendent leurs territoires d’origine contre les éclatements locaux. Si le réseau d’accès radio (RAN) 5G, et les câbles en fibre optique qui y sont reliés, doivent être exploités pour les services commerciaux aux clients, un certain type de passerelle doit être en place pour siphonner le trafic des clients privés du trafic des télécoms. L’architecture d’une telle passerelle existe déjà, et a été officiellement adoptée par le 3GPP. Elle s’appelle Local Breakout et fait également partie de la déclaration officielle de l’organisme de normalisation ETSI sur l’informatique périphérique multi-accès (MEC). Techniquement, ce problème a donc été résolu. L’ennui, c’est que certaines entreprises de télécommunications peuvent avoir intérêt à empêcher le détournement du trafic de leurs clients de la voie qu’il emprunterait normalement : vers leurs propres centres de données. La topologie actuelle du réseau Internet comporte trois niveaux : Les fournisseurs de services de niveau 1 ne s’échangent que des informations entre eux, tandis que les ISP de niveau 2 sont généralement en contact avec les clients. Le troisième niveau permet l’existence de petits ISP régionaux à un niveau plus local. L’informatique de périphérie à l’échelle mondiale pourrait devenir le catalyseur de services de type « nuage public », offerts par les FAI au niveau local, peut-être par le biais d’une sorte de « chaîne de magasins ». Mais cela suppose que les opérateurs de télécommunications, qui gèrent le niveau 2, soient prêts à laisser le trafic réseau entrant être réparti sur un troisième niveau, permettant ainsi la concurrence sur un marché qu’ils pourraient très facilement s’approprier.
Si l’emplacement, l’emplacement, l’emplacement compte à nouveau pour l’entreprise, alors l’ensemble du marché de l’informatique d’entreprise peut être bouleversé. La nature hyperscale, centralisée et gourmande en énergie des centres de données en nuage pourrait finir par jouer contre eux, alors que des modèles d’exploitation plus petits, plus agiles et plus rentables surgissent – comme des pissenlits, si tout se passe comme prévu – dans des emplacements plus largement répartis.
« Je pense que l’intérêt pour les déploiements en périphérie », a fait remarquer Kurt Marko, directeur de la société d’analyse technologique Marko Insights, dans une note adressée à ZDNet, « est principalement motivé par la nécessité de traiter des quantités massives de données générées par des appareils « intelligents », des capteurs et des utilisateurs – en particulier des utilisateurs mobiles/sans fil ». En effet, les taux de données et le débit des réseaux 5G, ainsi que l’escalade de l’utilisation des données par les clients, exigeront que les stations de base mobiles deviennent des mini-centres de données. »
Que signifie « edge computing » ?
Dans tout réseau de télécommunications, la périphérie est la portée la plus éloignée de ses installations et services vers ses clients. Dans le contexte de l’informatique périphérique, la périphérie est l’endroit de la planète où les serveurs peuvent fournir des fonctionnalités aux clients le plus rapidement possible.
Comment les CDN ont ouvert la voie

Diagramme de la relation entre les centres de données et les appareils de l’Internet des objets, tel que représenté par l’Industrial Internet Consortium.
En ce qui concerne l’Internet, l’informatique ou le traitement est effectué par des serveurs – des composants généralement représentés par une forme (par exemple, un nuage) près du centre ou du point focal d’un diagramme de réseau. Les données sont collectées à partir de dispositifs situés sur les bords de ce diagramme, puis acheminées vers le centre pour y être traitées. Les données traitées, comme le pétrole d’une raffinerie, sont pompées vers la périphérie pour être livrées. Les CDN accélèrent ce processus en agissant comme des « stations de remplissage » pour les utilisateurs à proximité. Le cycle de vie typique des services réseau implique ce processus « aller-retour », où les données sont effectivement extraites, expédiées, raffinées et réexpédiées. Et, comme dans tout processus qui implique la logistique, le transport prend du temps.
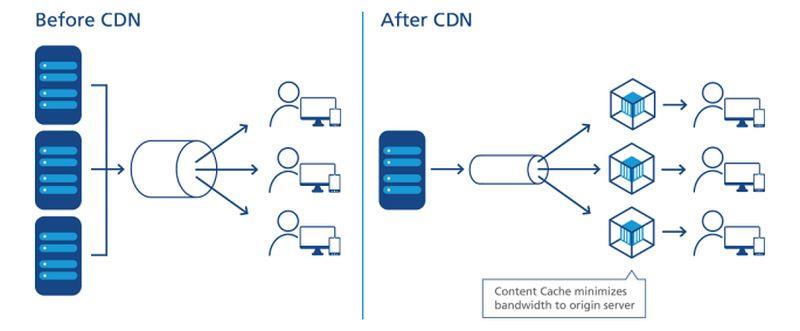
Un placement figuratif précis des serveurs CDN dans le processus de livraison des données.
NTT Communictions
Important, le fait que le CDN réside toujours au centre du diagramme, dépend du diagramme de qui vous regardez. Si c’est le fournisseur de CDN qui l’a dessiné, il peut y avoir un grand nuage « CDN » au centre, avec des réseaux d’entreprise le long des bords d’un côté, et des dispositifs d’équipement des utilisateurs le long des autres bords. Une exception est faite par NTT, dont le schéma simplifié mais plus précis ci-dessus montre des serveurs CDN s’injectant entre le point d’accès aux données et les utilisateurs. Du point de vue des producteurs de données ou de contenu, par opposition aux agents de distribution, les CDN se situent à la fin de la chaîne d’approvisionnement, c’est-à-dire à l’avant-dernière étape avant que l’utilisateur ne reçoive les données.
Au cours de la dernière décennie, les principaux fournisseurs de CDN ont commencé à introduire des services informatiques qui résident au point de livraison. Imaginez qu’une station-service puisse être sa propre raffinerie, et vous comprenez l’idée. La proposition de valeur de ce service dépend du fait que les CDN sont perçus non pas au centre, mais à la périphérie. Il permet à certaines données de contourner le besoin de transport, juste pour être traitées et transportées en retour.
La tendance à la décentralisation
Si les CDN n’ont pas encore prouvé l’efficacité de l’edge computing en tant que service, ils en ont au moins démontré la valeur en tant qu’entreprise : Les entreprises paieront des primes pour que certaines données soient traitées avant qu’elles n’atteignent le centre, ou « cœur », du réseau.
« Nous avons connu une assez longue période de centralisation », a expliqué Matt Baker, vice-président senior de Dell Technologies pour la stratégie et la planification, lors d’une conférence de presse en février dernier. « Et comme le monde cherche à offrir des expériences numériques de plus en plus en temps réel à travers leurs initiatives de transformation numérique, la capacité à s’accrocher à cette approche hautement centralisée de l’informatique commence à se fracturer assez fortement. »
L’informatique de pointe a été présentée comme l’un des nouveaux marchés lucratifs rendus possibles par la technologie sans fil 5G. Pour que la transition mondiale de la 4G à la 5G soit économiquement réalisable pour de nombreuses entreprises de télécommunications, la nouvelle génération doit ouvrir de nouveaux canaux de revenus exploitables. La 5G nécessite un vaste et nouveau réseau de connexions (ironiquement) filaires en fibre optique pour alimenter les émetteurs et les stations de base en accès instantané aux données numériques (le backhaul). Par conséquent, une nouvelle catégorie de fournisseurs de services informatiques a la possibilité de déployer plusieurs µDC adjacents aux tours du réseau d’accès radio (RAN), peut-être à côté ou dans le même bâtiment que les stations de base des opérateurs de télécommunications. Ces centres de données pourraient collectivement offrir des services de cloud computing à des clients sélectionnés à des tarifs compétitifs et des caractéristiques comparables à ceux des fournisseurs de cloud hyperscale tels qu’Amazon, Microsoft Azure et Google Cloud Platform.
Idéalement, peut-être après une dizaine d’années d’évolution, l’informatique de périphérie apporterait des services rapides aux clients aussi proches que leurs stations de base sans fil les plus proches. Nous aurions besoin d’énormes tuyaux de fibre optique pour fournir le backhaul nécessaire, mais les revenus des services de edge computing pourraient, de manière concevable, financer leur construction, ce qui lui permettrait de s’autofinancer.
Objectifs de niveau de service
En dernière analyse (si, en fait, toute analyse a jamais été finale), le succès ou l’échec des centres de données en périphérie des réseaux sera déterminé par leur capacité à atteindre les objectifs de niveau de service (SLO). Il s’agit des attentes des clients qui paient pour des services, telles qu’elles sont codifiées dans leurs contrats de service. Les ingénieurs disposent de mesures qu’ils utilisent pour enregistrer et analyser les performances des composants du réseau. Les clients ont tendance à éviter ces mesures, préférant privilégier les performances observables de leurs applications. Si un déploiement en périphérie n’est pas sensiblement plus rapide qu’un déploiement hyperscale, alors la périphérie en tant que concept pourrait mourir à ses débuts.
« Qu’est-ce qui nous importe ? C’est le temps de réponse des applications », a expliqué Tom Gillis, vice-président senior de VMware pour les réseaux et la sécurité, lors d’une récente conférence de l’entreprise. « Si nous pouvons caractériser la façon dont l’application répond, et examiner les composants individuels qui travaillent pour fournir cette réponse applicative, nous pouvons réellement commencer à créer cette infrastructure auto-réparatrice. »
La réduction de la latence et l’amélioration de la vitesse de traitement (avec des serveurs plus récents dédiés à beaucoup moins de tâches quantitativement) devraient jouer en faveur des ALS. Certains ont également souligné comment la large répartition des ressources sur une zone contribue à la redondance des services et même à la continuité des activités – qui, du moins jusqu’à la pandémie, étaient perçues comme des événements d’un ou deux jours, suivis de périodes de récupération.
Mais il y aura des facteurs d’équilibre, dont le plus important concerne la maintenance et l’entretien. Une installation typique de centre de données de niveau 2 peut être entretenue, dans des circonstances d’urgence (comme une pandémie) par seulement deux personnes sur place, avec du personnel de soutien hors site. En revanche, un µDC est conçu pour fonctionner sans avoir besoin d’un personnel permanent. Ses fonctions de surveillance intégrées envoient en permanence des données télémétriques à un concentrateur central, qui pourrait théoriquement se trouver dans le nuage public. Tant qu’un µDC remplit ses ALS, il n’a pas besoin d’être personnellement suivi.
C’est ici que la viabilité du modèle d’informatique périphérique doit encore être testée en profondeur. Avec un contrat typique de fournisseur de centre de données, un SLO est souvent mesuré par la rapidité avec laquelle le personnel du fournisseur peut résoudre un problème en suspens. En général, les délais de résolution peuvent rester faibles lorsque le personnel n’a pas à se rendre sur les lieux du problème par camion. Si un modèle de déploiement en périphérie doit être compétitif par rapport à un modèle de déploiement en colocation, ses capacités de remédiation automatisée ont intérêt à être incroyablement bonnes.
Le réseau hiérarchisé
Les fournisseurs de stockage de données, les hébergeurs d’applications natives du cloud, les fournisseurs de services de l’Internet des objets (IoT), les fabricants de serveurs, les sociétés d’investissement immobilier (REIT) et les fabricants de boîtiers de serveurs préassemblés, pavent tous des routes express entre leurs clients et ce qui promet, pour chacun d’entre eux, d’être la périphérie.
Ce qu’ils recherchent tous en réalité, c’est un avantage concurrentiel. L’idée d’un avantage donne un nouvel espoir aux perspectives d’un service de qualité supérieure – une raison solide et justifiable pour que certaines catégories de services soient facturées plus cher que d’autres. Si vous avez lu ou entendu ailleurs que la périphérie pourrait finalement englober l’ensemble du nuage, vous comprenez peut-être maintenant que cela n’aurait pas beaucoup de sens. Si tout était premium, rien ne le serait.
« L’Edge Computing va apparemment être la solution technologique parfaite, et les capital-risqueurs disent que ce sera un marché technologique de plusieurs milliards de dollars », a remarqué Kevin Brown, CTO et vice-président senior pour l’innovation chez le fournisseur d’équipements de services pour centres de données, et fabricant de châssis pour micro-centre de données, Schneider Electric. « Personne ne sait réellement ce que c’est ».

Kevin Brown de Schneider Electric : » Personne ne sait réellement ce que c’est. »
Brown a reconnu que l’edge computing peut attribuer son histoire aux CDN pionniers, comme Akamai. Pourtant, a-t-il poursuivi, » vous avez toutes ces différentes couches – HPE a sa version, Cisco a la sienne. . . Nous ne pouvions pas donner de sens à tout cela. Notre vision de la périphérie est vraiment une vision très simplifiée. À l’avenir, il y aura trois types de centres de données dans le monde, dont il faudra vraiment se préoccuper. »
Le tableau que Brown a dessiné, lors d’un événement de presse au siège de l’entreprise dans le Massachusetts en février 2019, est une vision réémergente d’un Internet à trois niveaux, et est partagé par un nombre croissant d’entreprises technologiques. Dans le modèle traditionnel à deux niveaux, les nœuds de niveau 1 sont limités à l’échange de trafic avec d’autres nœuds de niveau 1, tandis que les nœuds de niveau 2 gèrent la distribution des données au niveau régional. Depuis le début de l’Internet, il existe une désignation pour le niveau 3 – pour un accès à un niveau beaucoup plus local. (Comparez cela au schéma du réseau d’accès radio cellulaire, dont la distribution du trafic est à un seul niveau).
« Le premier point où vous vous connectez au réseau, est vraiment ce que nous considérons comme le bord local », a expliqué Brown. Mappé sur la technologie d’aujourd’hui, a-t-il poursuivi, vous pourriez trouver l’une des installations informatiques de périphérie d’aujourd’hui dans n’importe quel serveur poussé dans un rack de fortune dans un placard de câblage.
« Pour nos besoins, a-t-il poursuivi, nous pensons que c’est là que se trouve l’action. »
« La périphérie, pendant des années, était les hôtels de transporteurs de niveau 1 comme Equinix et CoreSite. Ils mettaient essentiellement en couche un réseau se connectant à un autre, et cela était considéré comme une périphérie », a expliqué Wen Temitim, directeur technique du fournisseur de services d’infrastructure de périphérie StackPath. « Mais ce que nous voyons, avec tous les différents changements d’utilisation basés sur le comportement des consommateurs, et avec COVID-19 et le travail à domicile, c’est un nouveau bord plus profond qui devient plus pertinent avec les fournisseurs de services. »
La localisation de la périphérie sur une carte
L’informatique de périphérie est un effort pour ramener la qualité de service (QoS) dans la discussion sur l’architecture et les services des centres de données, car les entreprises décident non seulement qui fournira leurs services, mais aussi où.
La « technologie opérationnelle de pointe »
Le fabricant d’équipements pour centres de données HPE – un investisseur majeur dans l’informatique de pointe – pense que le prochain saut géant dans l’infrastructure opérationnelle sera coordonné et dirigé par des employés et des entrepreneurs qui n’ont pas forcément beaucoup, voire pas du tout, d’investissement personnel ou de formation dans le matériel et l’infrastructure – des personnes qui, jusqu’à présent, ont été largement chargées de la maintenance, de l’entretien et du support logiciel. Son entreprise appelle cette catégorie de personnel « technologie opérationnelle » (OT). Contrairement à ceux qui perçoivent la convergence de l’informatique et des opérations dans une forme ou une autre de « DevOps », HPE perçoit trois classes de clients de l’informatique périphérique. Non seulement chacune de ces classes, selon lui, conservera sa propre plateforme d’edge computing, mais la géographie de ces plateformes se séparera les unes des autres, et non convergera, comme le décrit ce diagramme de HPE.

Ici, il y a trois classes distinctes de clients, chacune desquelles HPE a réparti son propre segment de l’edge au sens large. La classe OT désigne ici les clients plus susceptibles d’affecter à l’edge computing des responsables ayant une expérience moins directe de l’informatique, principalement parce que leurs principaux produits ne sont pas l’information ou les communications proprement dites. Cette classe se voit attribuer un « edge OT ». Lorsqu’une entreprise a un investissement plus direct dans l’information en tant qu’industrie, ou qu’elle dépend largement de l’information en tant que composante de son activité, HPE lui attribue un « IT edge ». Entre les deux, pour les entreprises qui sont géographiquement dispersées et dépendent de la logistique (où l’information a une composante plus logique) et donc de l’Internet des objets, HPE lui attribue un « IoT edge. »
Le réseau tripartite de Dell

En 2017, Dell Technologies a proposé pour la première fois sa topologie à trois niveaux pour le marché informatique dans son ensemble, le divisant en « core », « cloud » et « edge ». Comme l’indique cette diapositive d’une première présentation de Dell, cette division semblait radicalement simple, du moins au début : Les actifs informatiques de n’importe quel client pouvaient être divisés, respectivement, en 1) ce qu’il possède et entretient avec son propre personnel ; 2) ce qu’il délègue à un fournisseur de services et l’engage pour l’entretenir ; et 3) ce qu’il distribue au-delà de ses installations domestiques sur le terrain, pour être entretenu par des professionnels de l’exploitation (qui peuvent ou non être externalisés).
Dans une présentation de novembre 2018 pour la conférence Embedded Linux Conference Europe de la Linux Foundation, le directeur technique pour l’IoT et l’Edge Computing Jason Shepherd a présenté ce cas simple : Autant de dispositifs et d’appareils en réseau sont prévus pour l’IoT, autant il sera technologiquement impossible de centraliser leur gestion, y compris si nous enrôlons le cloud public.
« Ma femme et moi avons trois chats », a déclaré Shepherd à son auditoire. « Nous avons obtenu des capacités de stockage plus importantes sur nos téléphones, afin de pouvoir envoyer des vidéos de chats dans les deux sens ».

« Les vidéos de chats expliquent le besoin d’informatique périphérique », a-t-il poursuivi. « Si je mets une de mes vidéos en ligne, et qu’elle commence à recevoir des visites, je dois la mettre en cache sur plus de serveurs, loin derrière dans le cloud. Si elle devient virale, je dois déplacer ce contenu aussi près des abonnés que possible. En tant que telco, ou en tant que Netflix ou autre, le plus proche que je puisse avoir est à la périphérie du nuage – au pied de mes tours cellulaires, ces points clés sur Internet. C’est le concept de MEC, Multi-access Edge Computing – rapprocher le contenu des abonnés. Maintenant, si j’ai des milliards d’appelants connectés, j’ai complètement inversé le paradigme. Au lieu que les choses essaient de tirer vers le bas, j’ai tous ces appareils qui essaient de pousser vers le haut. Cela vous oblige à pousser l’informatique encore plus bas. »
Le « edge cloud » émergent
Depuis la première mondiale du chaton effrayé de Shepherd, le concept de Dell sur la périphérie s’est quelque peu durci, passant d’un assemblage nuancé de couches à une éthique de décentralisation plus basique.
« Nous voyons l’edge comme étant vraiment défini non pas nécessairement par un lieu spécifique ou une technologie spécifique », a déclaré Matt Baker de Dell en février dernier. « Il s’agit plutôt d’une complication du déploiement actuel de l’informatique dans la mesure où, parce que nous décentralisons de plus en plus nos environnements informatiques, nous constatons que nous plaçons des solutions d’infrastructure informatique, des logiciels, etc. dans des environnements de plus en plus contraints. Un centre de données est un environnement largement dépourvu de contraintes ; vous le construisez selon les spécifications que vous souhaitez, vous pouvez le refroidir de manière adéquate, il y a beaucoup d’espace. Mais comme nous plaçons de plus en plus de technologie dans le monde qui nous entoure, pour faciliter la fourniture de ces expériences numériques en temps réel, nous nous retrouvons dans des endroits qui sont mis au défi d’une certaine manière. »
Les réseaux de campus, a déclaré Baker, comprennent des équipements qui ont tendance à être poussiéreux et sales, en plus d’avoir une connectivité à faible bande passante. Les environnements Telco comprennent souvent des racks à très faible profondeur nécessitant une population de processeurs à très haute densité. Et dans les endroits les plus éloignés sur la carte, il y a une pénurie de main-d’œuvre informatique qualifiée, « ce qui met davantage de pression sur la capacité à gérer des environnements hautement distribués dans un mains-off, sans personnel. »
Néanmoins, il incombe à un nombre croissant de clients de traiter les données plus près du point où elles sont évaluées ou créées pour la première fois, a-t-il fait valoir. Cela place l’emplacement du « bord », vers 2020, à n’importe quel point de la carte où vous trouverez des données, faute d’une meilleure description, prenant feu.
Temitim de StackPath pense que ce point est un concept émergent appelé le cloud de périphérie – en fait une collection virtuelle de multiples déploiements de périphérie dans une seule plate-forme. Cette plateforme serait commercialisée dans un premier temps auprès des distributeurs vidéo multicanaux (MVPD, généralement les câblo-opérateurs historiques mais aussi certains telcos) qui cherchent à posséder leurs propres réseaux de distribution, et à réduire leurs coûts à long terme. Mais comme source de revenus supplémentaires, ces fournisseurs pourraient ensuite proposer des services de type « cloud public », tels que des applications SaaS ou même l’hébergement de serveurs virtuels, pour le compte de clients commerciaux.
Un tel marché du « edge cloud » pourrait concurrencer directement les centres de données de niveau 2 et 3 de taille moyenne dans le monde. Étant donné que les opérateurs de ces installations sont généralement des clients privilégiés des entreprises de télécommunications de leurs régions respectives, ces entreprises pourraient percevoir le nuage de périphérie comme une menace concurrentielle pour leurs propres plans de 5G sans fil. Il s’agit véritablement, comme l’a dit un fournisseur d’infrastructure de périphérie, d’une « prise de terrain physique ». Et l’accaparement ne fait vraiment que commencer.
En savoir plus – Du réseau interactif CBS
- Comment l’informatique de périphérie peut réorganiser, revitaliser l’immobilier commercial par Larry Dignan, Between the Lines
- C’est une course à la périphérie, et la fin du cloud computing tel que nous le connaissons par Scott M. Fulton, III, Scale
- Faites de l’edge computing un investissement clé pour 2020 par Forrester Research
Ailleurs
- Le centre de données qui est une table basse par Scott M. Fulton, III, Data Center Knowledge
- Dell Joins AT&T to Move Edge Data Centers Wherever They Should Be by Scott M. Fulton, III, Data Center Knowledge
- Challenges and Solutions in Edge Computing: The Future by Pam Baker, Linux.com