Dernière mise à jour le 19 juillet 2019
Les réseaux adversariaux génératifs, ou GAN pour faire court, sont une approche de la modélisation générative utilisant des méthodes d’apprentissage profond, comme les réseaux neuronaux convolutifs.
La modélisation générative est une tâche d’apprentissage non supervisée en apprentissage automatique qui consiste à découvrir et à apprendre automatiquement les régularités ou les modèles dans les données d’entrée de telle sorte que le modèle puisse être utilisé pour générer ou sortir de nouveaux exemples qui auraient pu plausiblement être tirés de l’ensemble de données d’origine.
Les GAN sont une façon astucieuse d’entraîner un modèle génératif en formulant le problème comme un problème d’apprentissage supervisé avec deux sous-modèles : le modèle générateur que nous entraînons pour générer de nouveaux exemples, et le modèle discriminateur qui tente de classer les exemples comme réels (provenant du domaine) ou faux (générés). Les deux modèles sont entraînés ensemble dans un jeu à somme nulle, contradictoire, jusqu’à ce que le modèle discriminateur soit trompé environ la moitié du temps, ce qui signifie que le modèle générateur génère des exemples plausibles.
Les GAN sont un domaine passionnant et en évolution rapide, qui tient la promesse des modèles génératifs dans leur capacité à générer des exemples réalistes dans un éventail de domaines de problèmes, plus particulièrement dans les tâches de traduction d’image à image telles que la traduction de photos d’été en hiver ou de jour en nuit, et dans la génération de photos photoréalistes d’objets, de scènes et de personnes que même les humains ne peuvent pas dire qu’elles sont fausses.
Dans ce billet, vous découvrirez une introduction douce aux réseaux adversariaux génératifs, ou GANs.
Après avoir lu ce billet, vous saurez :
- Contexte des GANs, y compris l’apprentissage supervisé vs non supervisé et la modélisation discriminative vs générative.
- Les GAN sont une architecture pour l’apprentissage automatique d’un modèle génératif en traitant le problème non supervisé comme supervisé et en utilisant à la fois un modèle génératif et un modèle discriminant.
- Les GAN offrent une voie vers une augmentation sophistiquée des données spécifiques au domaine et une solution aux problèmes qui nécessitent une solution générative, comme la traduction image à image.
Démarrez votre projet avec mon nouveau livre Generative Adversarial Networks with Python, comprenant des tutoriels étape par étape et les fichiers de code source Python pour tous les exemples.
Démarrons.

Une douce introduction aux réseaux adversariaux génératifs (GAN)
Photo de Barney Moss, certains droits réservés.
- Overview
- Qu’est-ce que les modèles génératifs ?
- Apprentissage supervisé vs. Apprentissage non supervisé
- Vous voulez développer des GANs à partir de zéro ?
- Modélisation discriminante vs. Modélisation générative
- Exemples de modèles génératifs
- Qu’est-ce que les réseaux adversariaux génératifs ?
- Le modèle générateur
- Le modèle discriminateur
- Les GAN comme un jeu à deux joueurs
- Les GAN et les réseaux de neurones convolutifs
- Les GAN conditionnels
- Pourquoi des réseaux adversariaux génératifs ?
- Lectures complémentaires
- Posts
- Books
- Papers
- Articles
- Sommaire
- Develop Generative Adversarial Networks Today!
- Develop Your GAN Models in Minutes
- Finally Bring GAN Models to your Vision Projects
Overview
Ce tutoriel est divisé en trois parties ; ce sont :
- Que sont les modèles génératifs ?
- Que sont les réseaux adversariaux génératifs ?
- Pourquoi des réseaux adversariaux génératifs ?
Qu’est-ce que les modèles génératifs ?
Dans cette section, nous passerons en revue l’idée des modèles génératifs, en enjambant les paradigmes d’apprentissage supervisé vs non supervisé et la modélisation discriminative vs générative.
Apprentissage supervisé vs. Apprentissage non supervisé
Un problème typique d’apprentissage automatique implique l’utilisation d’un modèle pour faire une prédiction, par exemple la modélisation prédictive.
Cela nécessite un ensemble de données d’entraînement qui est utilisé pour entraîner un modèle, composé de multiples exemples, appelés échantillons, chacun avec des variables d’entrée (X) et des étiquettes de classe de sortie (y). Un modèle est entraîné en montrant des exemples d’entrées, en lui faisant prédire des sorties, et en corrigeant le modèle pour que les sorties ressemblent davantage aux sorties attendues.
Dans l’approche prédictive ou d’apprentissage supervisé, l’objectif est d’apprendre une correspondance entre les entrées x et les sorties y, étant donné un ensemble étiqueté de paires d’entrées-sorties…
– Page 2, Machine Learning : A Probabilistic Perspective, 2012.
Cette correction du modèle est généralement désignée comme une forme d’apprentissage supervisé, ou apprentissage supervisé.
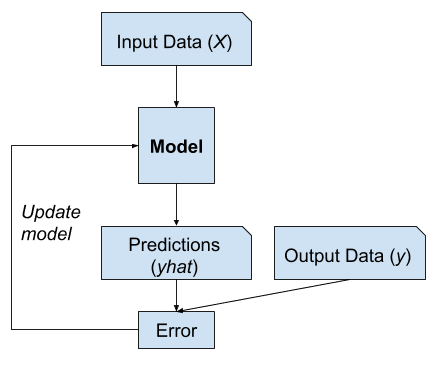
Exemple d’apprentissage supervisé
Des exemples de problèmes d’apprentissage supervisé incluent la classification et la régression, et des exemples d’algorithmes d’apprentissage supervisé incluent la régression logistique et la forêt aléatoire.
Il existe un autre paradigme d’apprentissage où le modèle ne reçoit que les variables d’entrée (X) et le problème ne comporte pas de variables de sortie (y).
Un modèle est construit en extrayant ou en résumant les modèles dans les données d’entrée. Il n’y a pas de correction du modèle, car le modèle ne prédit rien.
Le deuxième grand type d’apprentissage automatique est l’approche descriptive ou d’apprentissage non supervisé. Ici, on ne nous donne que des entrées, et le but est de trouver des « modèles intéressants » dans les données. Il s’agit d’un problème beaucoup moins bien défini, car on ne nous dit pas quels types de motifs rechercher, et il n’y a pas de métrique d’erreur évidente à utiliser (contrairement à l’apprentissage supervisé, où nous pouvons comparer notre prédiction de y pour un x donné à la valeur observée).
– Page 2, Machine Learning : A Probabilistic Perspective, 2012.
Cette absence de correction est généralement désignée comme une forme d’apprentissage non supervisé, ou apprentissage non supervisé.
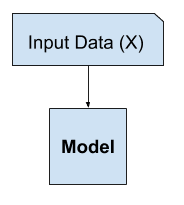
Exemple d’apprentissage non supervisé
Des exemples de problèmes d’apprentissage non supervisé incluent le regroupement et la modélisation générative, et des exemples d’algorithmes d’apprentissage non supervisé sont K-means et les réseaux adversariens génératifs.
Vous voulez développer des GANs à partir de zéro ?
Suivez dès maintenant mon cours accéléré gratuit de 7 jours par courriel (avec un exemple de code).
Cliquez pour vous inscrire et obtenir également une version PDF Ebook gratuite du cours.
Téléchargez votre mini-cours GRATUIT
Modélisation discriminante vs. Modélisation générative
Dans l’apprentissage supervisé, nous pouvons être intéressés par le développement d’un modèle pour prédire une étiquette de classe étant donné un exemple de variables d’entrée.
Cette tâche de modélisation prédictive est appelée classification.
La classification est aussi traditionnellement appelée modélisation discriminative.
… nous utilisons les données d’apprentissage pour trouver une fonction discriminante f(x) qui fait correspondre chaque x directement à une étiquette de classe, combinant ainsi les étapes d’inférence et de décision en un seul problème d’apprentissage.
— Page 44, Pattern Recognition and Machine Learning, 2006.
This is because a model must discriminate examples of input variables across classes; it must choose or make a decision as to what class a given example belongs.
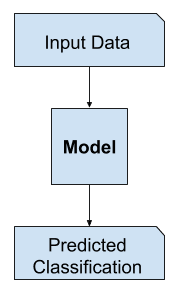
Example of Discriminative Modeling
Alternately, unsupervised models that summarize the distribution of input variables may be able to be used to create or generate new examples in the input distribution.
As such, these types of models are referred to as generative models.
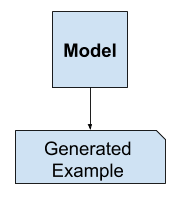
Example of Generative Modeling
For example, a single variable may have a known data distribution, such as a Gaussian distribution, or bell shape. Un modèle génératif peut être capable de résumer suffisamment cette distribution de données, puis être utilisé pour générer de nouvelles variables qui s’inscrivent de manière plausible dans la distribution de la variable d’entrée.
Les approches qui modélisent explicitement ou implicitement la distribution des entrées ainsi que des sorties sont connues sous le nom de modèles génératifs, car en les échantillonnant, il est possible de générer des points de données synthétiques dans l’espace d’entrée.
– Page 43, Pattern Recognition and Machine Learning, 2006.
En fait, un très bon modèle génératif peut être capable de générer de nouveaux exemples qui ne sont pas seulement plausibles, mais indiscernables des exemples réels du domaine du problème.
Exemples de modèles génératifs
Naive Bayes est un exemple de modèle génératif qui est plus souvent utilisé comme modèle discriminant.
Par exemple, Naive Bayes fonctionne en résumant la distribution de probabilité de chaque variable d’entrée et de la classe de sortie. Lorsqu’une prédiction est faite, la probabilité de chaque résultat possible est calculée pour chaque variable, les probabilités indépendantes sont combinées et le résultat le plus probable est prédit. Utilisé à l’inverse, les distributions de probabilité pour chaque variable peuvent être échantillonnées pour générer de nouvelles valeurs de caractéristiques plausibles (indépendantes).
L’allocation de Dirichlet latente, ou LDA, et le modèle de mélange gaussien, ou GMM, sont d’autres exemples de modèles génératifs.
Les méthodes d’apprentissage profond peuvent être utilisées comme modèles génératifs. Deux exemples populaires incluent la machine de Boltzmann restreinte, ou RBM, et le réseau de croyance profond, ou DBN.
Deux exemples modernes d’algorithmes de modélisation générative d’apprentissage profond incluent l’autoencodeur variationnel, ou VAE, et le réseau adversarial génératif, ou GAN.
Qu’est-ce que les réseaux adversariaux génératifs ?
Les réseaux adversariaux génératifs, ou GAN, sont un modèle génératif basé sur l’apprentissage profond.
Plus généralement, les GAN sont une architecture de modèle pour l’entraînement d’un modèle génératif, et il est plus courant d’utiliser des modèles d’apprentissage profond dans cette architecture.
L’architecture GAN a été décrite pour la première fois dans l’article de 2014 de Ian Goodfellow, et al. intitulé « Generative Adversarial Networks »
Une approche standardisée appelée Deep Convolutional Generative Adversarial Networks, ou DCGAN, qui a conduit à des modèles plus stables a ensuite été formalisée par Alec Radford, et al. dans l’article de 2015 intitulé » Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks « .
La plupart des GANs actuels sont au moins vaguement basés sur l’architecture DCGAN…
– NIPS 2016 Tutorial : Generative Adversarial Networks, 2016.
L’architecture du modèle GAN implique deux sous-modèles : un modèle générateur pour générer de nouveaux exemples et un modèle discriminateur pour classer si les exemples générés sont réels, issus du domaine, ou faux, générés par le modèle générateur.
- Générateur. Modèle qui est utilisé pour générer de nouveaux exemples plausibles à partir du domaine problématique.
- Discriminateur. Modèle qui est utilisé pour classer les exemples comme réels (du domaine) ou faux (générés).
Les réseaux adversariaux génératifs sont basés sur un scénario de théorie des jeux dans lequel le réseau générateur doit rivaliser avec un adversaire. Le réseau générateur produit directement des échantillons. Son adversaire, le réseau discriminateur, tente de distinguer les échantillons tirés des données d’entraînement des échantillons tirés du générateur.
– Page 699, Deep Learning, 2016.
Le modèle générateur
Le modèle générateur prend en entrée un vecteur aléatoire de longueur fixe et génère un échantillon dans le domaine.
Le vecteur est tiré au hasard d’une distribution gaussienne, et le vecteur est utilisé pour ensemencer le processus génératif. Après l’apprentissage, les points de cet espace vectoriel multidimensionnel correspondront aux points du domaine du problème, formant une représentation comprimée de la distribution des données.
Cet espace vectoriel est appelé espace latent, ou espace vectoriel composé de variables latentes. Les variables latentes, ou variables cachées, sont les variables qui sont importantes pour un domaine mais qui ne sont pas directement observables.
Une variable latente est une variable aléatoire que nous ne pouvons pas observer directement.
– Page 67, Deep Learning, 2016.
Nous faisons souvent référence aux variables latentes, ou à un espace latent, comme une projection ou une compression d’une distribution de données. Autrement dit, un espace latent fournit une compression ou des concepts de haut niveau des données brutes observées, telles que la distribution des données d’entrée. Dans le cas des GAN, le modèle générateur applique une signification aux points d’un espace latent choisi, de sorte que de nouveaux points tirés de l’espace latent peuvent être fournis au modèle générateur comme entrée et utilisés pour générer des exemples de sortie nouveaux et différents.
Les modèles d’apprentissage par la machine peuvent apprendre l’espace latent statistique des images, de la musique et des histoires, et ils peuvent ensuite échantillonner à partir de cet espace, créant de nouvelles œuvres d’art avec des caractéristiques similaires à celles que le modèle a vues dans ses données d’entraînement.
– Page 270, Deep Learning with Python, 2017.
Après l’entraînement, le modèle générateur est conservé et utilisé pour générer de nouveaux échantillons.
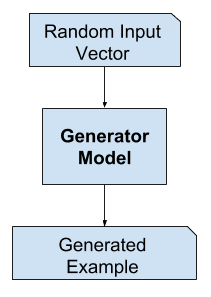
Exemple du modèle générateur de GAN
Le modèle discriminateur
Le modèle discriminateur prend un exemple du domaine en entrée (réel ou généré) et prédit une étiquette de classe binaire de vrai ou faux (généré).
L’exemple réel provient de l’ensemble de données d’entraînement. Les exemples générés sont sortis par le modèle générateur.
Le discriminateur est un modèle de classification normal (et bien compris).
Après le processus d’entraînement, le modèle discriminateur est écarté car nous nous intéressons au générateur.
Parfois, le générateur peut être repurposé car il a appris à extraire efficacement des caractéristiques du domaine problématique. Une partie ou la totalité des couches d’extraction de caractéristiques peuvent être utilisées dans des applications d’apprentissage par transfert utilisant des données d’entrée identiques ou similaires.
Nous proposons qu’une façon de construire de bonnes représentations d’images est d’entraîner des réseaux adversariaux génératifs (GAN), et de réutiliser plus tard des parties des réseaux générateurs et discriminateurs comme extracteurs de caractéristiques pour des tâches supervisées
– Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
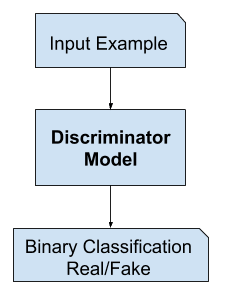
Exemple du modèle discriminant du GAN
Les GAN comme un jeu à deux joueurs
La modélisation générative est un problème d’apprentissage non supervisé, comme nous l’avons discuté dans la section précédente, bien qu’une propriété astucieuse de l’architecture GAN soit que l’entraînement du modèle génératif soit encadré comme un problème d’apprentissage supervisé.
Les deux modèles, le générateur et le discriminateur, sont entraînés ensemble. Le générateur génère un lot d’échantillons, et ceux-ci, ainsi que des exemples réels du domaine, sont fournis au discriminateur et classés comme vrais ou faux.
Le discriminateur est ensuite mis à jour pour s’améliorer dans la discrimination des vrais et faux échantillons au tour suivant, et, ce qui est important, le générateur est mis à jour en fonction de la façon dont, ou non, les échantillons ont trompé le discriminateur.
Nous pouvons considérer que le générateur est comme un faussaire, qui essaie de fabriquer de la fausse monnaie, et que le discriminateur est comme la police, qui essaie d’autoriser la monnaie légitime et d’attraper la fausse monnaie. Pour réussir dans ce jeu, le faussaire doit apprendre à fabriquer de l’argent indiscernable de l’argent authentique, et le réseau générateur doit apprendre à créer des échantillons tirés de la même distribution que les données d’entraînement.
– NIPS 2016 Tutorial : Generative Adversarial Networks, 2016.
De cette façon, les deux modèles sont en compétition l’un contre l’autre, ils sont adversaires au sens de la théorie des jeux, et jouent un jeu à somme nulle.
Parce que le cadre GAN peut naturellement être analysé avec les outils de la théorie des jeux, nous appelons les GANs « adversariaux ».
– NIPS 2016 Tutorial : Generative Adversarial Networks, 2016.
Dans ce cas, à somme nulle signifie que lorsque le discriminateur identifie avec succès les vrais et les faux échantillons, il est récompensé ou aucune modification n’est nécessaire aux paramètres du modèle, alors que le générateur est pénalisé par de grandes mises à jour des paramètres du modèle.
Alternativement, lorsque le générateur trompe le discriminateur, il est récompensé, ou aucun changement n’est nécessaire pour les paramètres du modèle, mais le discriminateur est pénalisé et ses paramètres de modèle sont mis à jour.
À une limite, le générateur génère des répliques parfaites du domaine d’entrée à chaque fois, et le discriminateur ne peut pas faire la différence et prédit « incertain » (par exemple 50% pour le vrai et le faux) dans tous les cas. Ceci n’est qu’un exemple de cas idéalisé ; nous n’avons pas besoin d’arriver à ce point pour arriver à un modèle de générateur utile.
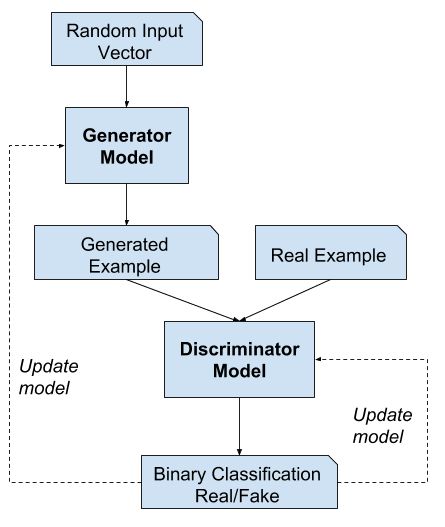
Exemple de l’architecture du modèle de réseau adversarial génératif
pilote le discriminateur pour tenter d’apprendre à classer correctement les échantillons comme vrais ou faux. Simultanément, le générateur tente de tromper le classificateur en lui faisant croire que ses échantillons sont réels. A la convergence, les échantillons du générateur sont indiscernables des données réelles, et le discriminateur sort 1/2 partout. Le discriminateur peut alors être écarté.
– Page 700, Deep Learning, 2016.
Les GAN et les réseaux de neurones convolutifs
Les GAN travaillent généralement avec des données d’image et utilisent des réseaux de neurones convolutifs, ou CNN, comme modèles de générateur et de discriminateur.
Cela peut s’expliquer à la fois par le fait que la première description de la technique se situait dans le domaine de la vision par ordinateur et utilisait des CNN et des données d’image, et par les progrès remarquables qui ont été constatés ces dernières années en utilisant plus généralement les CNN pour obtenir des résultats de pointe sur une série de tâches de vision par ordinateur telles que la détection d’objets et la reconnaissance de visages.
Modéliser des données d’image signifie que l’espace latent, l’entrée du générateur, fournit une représentation comprimée de l’ensemble des images ou des photographies utilisées pour entraîner le modèle. Cela signifie également que le générateur génère de nouvelles images ou photographies, fournissant une sortie qui peut être facilement visualisée et évaluée par les développeurs ou les utilisateurs du modèle.
C’est peut-être ce fait avant tout, la possibilité d’évaluer visuellement la qualité de la sortie générée, qui a à la fois conduit à la focalisation des applications de vision par ordinateur avec les CNN et aux bonds massifs dans la capacité des GAN par rapport à d’autres modèles génératifs, basés sur l’apprentissage profond ou autre.
Les GAN conditionnels
Une extension importante des GAN réside dans leur utilisation pour générer conditionnellement une sortie.
Le modèle génératif peut être entraîné à générer de nouveaux exemples à partir du domaine d’entrée, où l’entrée, le vecteur aléatoire de l’espace latent, est fournie avec (conditionnée par) une certaine entrée supplémentaire.
L’entrée supplémentaire pourrait être une valeur de classe, comme homme ou femme dans la génération de photographies de personnes, ou un chiffre, dans le cas de la génération d’images de chiffres manuscrits.
Les réseaux adversariens génératifs peuvent être étendus à un modèle conditionnel si le générateur et le discriminateur sont tous deux conditionnés par une information supplémentaire y. y pourrait être n’importe quel type d’information auxiliaire, comme des étiquettes de classe ou des données provenant d’autres modalités. Nous pouvons effectuer le conditionnement en alimentant y à la fois dans le discriminateur et le générateur comme couche d’entrée supplémentaire.
– Conditional Generative Adversarial Nets, 2014.
Le discriminateur est également conditionné, ce qui signifie qu’il reçoit à la fois une image d’entrée qui est soit réelle soit fausse et l’entrée supplémentaire. Dans le cas d’une entrée conditionnelle de type étiquette de classification, le discriminateur s’attendrait alors à ce que l’entrée soit de cette classe, apprenant à son tour au générateur à générer des exemples de cette classe afin de tromper le discriminateur.
De cette façon, un GAN conditionnel peut être utilisé pour générer des exemples d’un domaine d’un type donné.
Plus loin encore, les modèles GAN peuvent être conditionnés sur un exemple du domaine, comme une image. Cela permet des applications des GANs telles que la traduction texte-image, ou la traduction image-image. Cela permet certaines des applications les plus impressionnantes des GANs, comme le transfert de style, la colorisation de photos, la transformation de photos d’été en hiver ou de jour en nuit, et ainsi de suite.
Dans le cas des GANs conditionnels pour la traduction d’image à image, comme la transformation de jour en nuit, le discriminateur reçoit en entrée des photos de nuit réelles et générées, ainsi que (conditionnées sur) des photos de jour réelles. Le générateur reçoit un vecteur aléatoire de l’espace latent ainsi que (conditionné sur) des photos réelles de jour comme entrée.
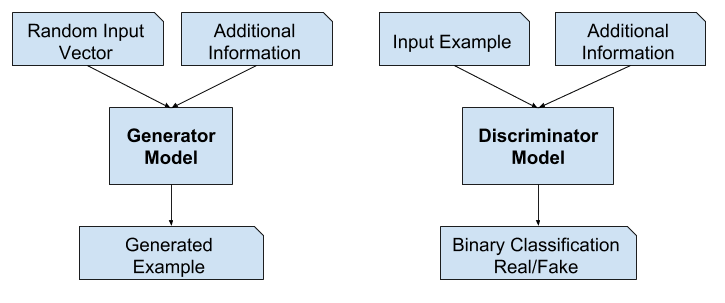
Exemple d’une architecture de modèle de réseau adversarial génératif conditionnel
Pourquoi des réseaux adversariaux génératifs ?
L’une des nombreuses avancées majeures dans l’utilisation des méthodes d’apprentissage profond dans des domaines tels que la vision par ordinateur est une technique appelée augmentation des données.
L’augmentation des données permet d’obtenir des modèles plus performants, en augmentant à la fois la compétence du modèle et en fournissant un effet de régularisation, réduisant ainsi l’erreur de généralisation. Elle fonctionne en créant de nouveaux exemples artificiels mais plausibles à partir du domaine problématique d’entrée sur lequel le modèle est entraîné.
Les techniques sont primitives dans le cas des données d’image, impliquant des recadrages, des retournements, des zooms et d’autres transformations simples d’images existantes dans l’ensemble de données d’entraînement.
La modélisation générative réussie fournit une approche alternative et potentiellement plus spécifique au domaine pour l’augmentation des données. En fait, l’augmentation des données est une version simplifiée de la modélisation générative, bien qu’elle soit rarement décrite de cette façon.
… en élargissant l’échantillon avec des données latentes (non observées). C’est ce qu’on appelle l’augmentation des données. Dans d’autres problèmes, les données latentes sont des données réelles qui auraient dû être observées mais qui sont manquantes.
– Page 276, The Elements of Statistical Learning, 2016.
Dans des domaines complexes ou des domaines avec une quantité limitée de données, la modélisation générative fournit une voie vers plus de formation pour la modélisation. Les GAN ont connu beaucoup de succès dans ce cas d’utilisation dans des domaines tels que l’apprentissage par renforcement profond.
Il existe de nombreuses raisons de recherche pour lesquelles les GAN sont intéressants, importants et nécessitent une étude plus approfondie. Ian Goodfellow en expose un certain nombre dans son discours-programme de la conférence de 2016 et dans le rapport technique associé intitulé » NIPS 2016 Tutorial : Generative Adversarial Networks. »
Parmi ces raisons, il souligne la capacité réussie des GAN à modéliser des données à haute dimension, à gérer les données manquantes et la capacité des GAN à fournir des sorties multimodales ou de multiples réponses plausibles.
Peut-être que l’application la plus convaincante des GAN concerne les GAN conditionnels pour les tâches qui nécessitent la génération de nouveaux exemples. Ici, Goodfellow indique trois exemples principaux :
- Super-résolution d’images. La capacité de générer des versions haute résolution d’images d’entrée.
- Création d’art. La capacité de créer des images nouvelles et artistiques, des croquis, des peintures, et plus encore.
- Traduction d’image à image. La capacité de traduire des photographies à travers des domaines, tels que le jour à la nuit, l’été à l’hiver, et plus encore.
Peut-être la raison la plus convaincante pour laquelle les GANs sont largement étudiés, développés et utilisés est leur succès. Les GAN ont été capables de générer des photos si réalistes que les humains sont incapables de dire qu’il s’agit d’objets, de scènes et de personnes qui n’existent pas dans la vie réelle.
Surprenant n’est pas un adjectif suffisant pour décrire leur capacité et leur succès.

Exemple de la progression des capacités des GAN de 2014 à 2017. Extrait de l’ouvrage The Malicious Use of Artificial Intelligence : Forecasting, Prevention, and Mitigation, 2018.
Lectures complémentaires
Cette section fournit plus de ressources sur le sujet si vous cherchez à approfondir.
Posts
- Best Resources for Getting Started With Generative Adversarial Networks (GANs)
- 18 Impressive Applications of Generative Adversarial Networks (GANs)
Books
- Chapter 20. Deep Generative Models, Deep Learning, 2016.
- Chapter 8. Generative Deep Learning, Deep Learning with Python, 2017.
- Machine Learning: A Probabilistic Perspective, 2012.
- Pattern Recognition and Machine Learning, 2006.
- The Elements of Statistical Learning, 2016.
Papers
- Generative Adversarial Networks, 2014.
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
- NIPS 2016 Tutorial: Generative Adversarial Networks, 2016.
- Conditional Generative Adversarial Nets, 2014.
- The Malicious Use of Artificial Intelligence: Prévision, prévention et atténuation, 2018.
Articles
- Modèle génératif, Wikipédia.
- Variable latente, Wikipédia.
- Réseau adversarial génératif, Wikipédia.
Sommaire
Dans ce billet, vous avez découvert une introduction douce aux réseaux adversariaux génératifs, ou GAN.
Spécifiquement, vous avez appris :
- Contexte des GAN, notamment l’apprentissage supervisé vs. L’apprentissage non supervisé et la modélisation discriminative vs générative.
- Les GANs sont une architecture permettant d’entraîner automatiquement un modèle génératif en traitant le problème non supervisé comme supervisé et en utilisant à la fois un modèle génératif et un modèle discriminatif.
- Les GANs offrent une voie vers une augmentation sophistiquée des données spécifiques au domaine et une solution aux problèmes qui nécessitent une solution générative, comme la traduction d’image à image.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Generative Adversarial Networks Today!

Develop Your GAN Models in Minutes
…with just a few lines of python code
Discover how in my new Ebook:
Generative Adversarial Networks with Python
It provides self-study tutorials and end-to-end projects on:
DCGAN, conditional GANs, image translation, Pix2Pix, CycleGAN
and much more…
Finally Bring GAN Models to your Vision Projects
Skip the Academics. Just Results.See What’s Inside