Ici, chez GutCheck, nous parlons beaucoup des 4 » V » du Big Data : volume, variété, vélocité et véracité. Il y a un » V » dont nous soulignons l’importance par rapport à tous les autres : la véracité. La véracité des données est le domaine qui présente encore un potentiel d’amélioration et constitue le plus grand défi en matière de Big Data. Avec autant de données disponibles, s’assurer qu’elles sont pertinentes et de haute qualité fait la différence entre ceux qui utilisent avec succès le big data et ceux qui peinent à le comprendre.
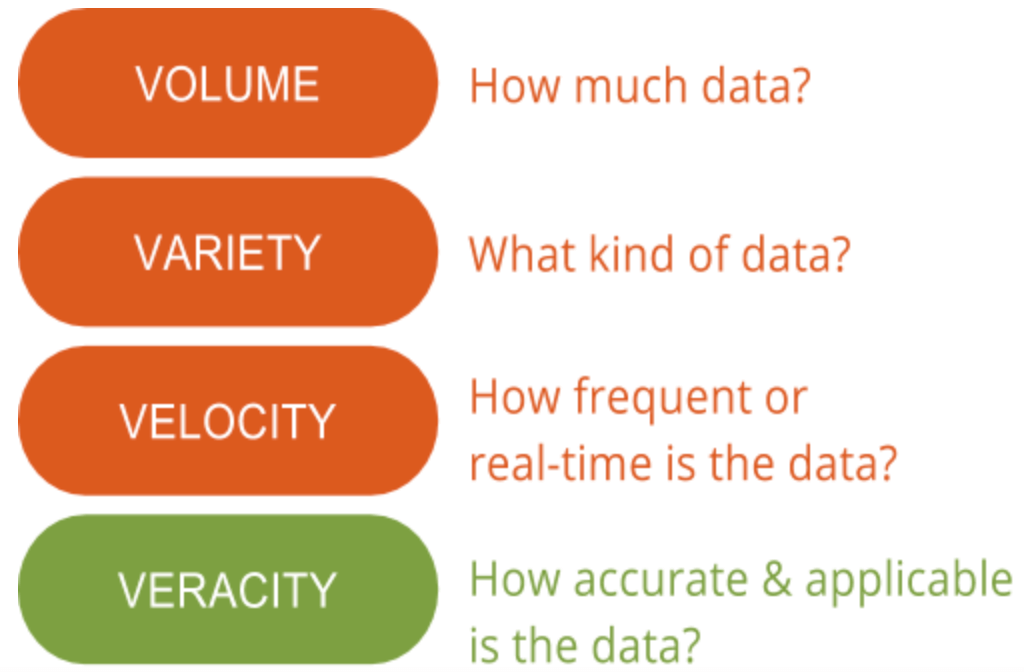 Comprendre l’importance de la véracité des données est la première étape pour discerner le signal du bruit lorsqu’il s’agit de big data. En d’autres termes, la véracité aide à filtrer ce qui est important et ce qui ne l’est pas, et au final, elle génère une compréhension plus profonde des données et de la manière de les contextualiser afin de prendre des mesures.
Comprendre l’importance de la véracité des données est la première étape pour discerner le signal du bruit lorsqu’il s’agit de big data. En d’autres termes, la véracité aide à filtrer ce qui est important et ce qui ne l’est pas, et au final, elle génère une compréhension plus profonde des données et de la manière de les contextualiser afin de prendre des mesures.
Qu’est-ce que la véracité des données ?
La véracité des données, en général, est la mesure dans laquelle un ensemble de données peut être précis ou véridique. Dans le contexte du big data, cependant, elle prend un peu plus de sens. Plus précisément, lorsqu’il s’agit de la véracité des big data, il ne s’agit pas seulement de la qualité des données elles-mêmes, mais de la fiabilité de la source, du type et du traitement des données. L’élimination d’éléments tels que les biais, les anomalies ou les incohérences, les doublons et la volatilité ne sont que quelques aspects qui entrent en ligne de compte dans l’amélioration de la précision des big data.
Malheureusement, la volatilité échappe parfois à notre contrôle. La volatilité, parfois appelée un autre « V » du big data, est le taux de changement et la durée de vie des données. Un exemple de données très volatiles est celui des médias sociaux, où les sentiments et les sujets d’actualité changent rapidement et souvent. Les données moins volatiles ressembleraient davantage à quelque chose comme les tendances météorologiques qui changent moins fréquemment et sont plus faciles à prévoir et à suivre.
Le deuxième côté de la véracité des données implique de s’assurer que la méthode de traitement des données réelles a du sens en fonction des besoins de l’entreprise et que le résultat est pertinent par rapport aux objectifs. Évidemment, cela est particulièrement important lorsqu’on incorpore des études de marché primaires avec le big data. L’interprétation correcte des big data garantit la pertinence des résultats et la possibilité de prendre des mesures. En outre, l’accès aux big data signifie que vous pourriez passer des mois à trier les informations sans vous concentrer et sans méthode pour identifier les points de données pertinents. Par conséquent, les données doivent être analysées en temps opportun, ce qui est difficile avec le big data, sinon les aperçus ne seraient pas utiles.
Pourquoi c’est important
Le big data est très complexe, et par conséquent, les moyens de le comprendre et de l’interpréter sont encore entièrement conceptualisés. Alors que beaucoup pensent que l’apprentissage automatique aura une grande utilité pour l’analyse des big data, les méthodes statistiques sont encore nécessaires pour assurer la qualité des données et l’application pratique des big data pour les études de marché. Par exemple, vous ne téléchargeriez pas un rapport sur l’industrie sur Internet et l’utiliseriez pour prendre des mesures. Au contraire, vous le valideriez probablement ou l’utiliseriez pour effectuer des recherches supplémentaires avant de formuler vos propres conclusions. Le big data n’est pas différent ; vous ne pouvez pas prendre le big data tel quel sans le valider ou l’expliquer. Mais contrairement à la plupart des pratiques d’études de marché, le big data n’a pas de base solide avec les statistiques.
C’est pourquoi nous avons passé du temps à comprendre les plateformes de gestion des données et le big data afin de continuer à défricher des méthodes qui intègrent, agrègent et interprètent les données avec une précision de niveau recherche comme les méthodes éprouvées auxquelles nous sommes habitués. Une partie de ces méthodes comprend l’indexation et le nettoyage des données, en plus de l’utilisation de données primaires pour aider à donner plus de contexte et maintenir la véracité des aperçus.
De nombreuses organisations ne peuvent pas passer tout le temps nécessaire pour vraiment discerner si une source de big data et une méthode de traitement soutiennent un haut niveau de véracité. Travailler avec un partenaire qui maîtrise les fondements du big data dans les études de marché peut aider. Pour savoir comment un de nos clients a exploité des informations basées sur des enquêtes et des données comportementales (big data), consultez l’étude de cas ci-dessous. Vous verrez également comment ils ont pu relier les points et libérer la puissance de l’intelligence d’audience pour conduire une meilleure stratégie de segmentation du consommateur.