Uit de vorige paragraaf moet duidelijk zijn dat, zelfs als de categorisering van de proefpersonen met betrekking tot blootstelling en uitkomst volkomen nauwkeurig is, bias kan worden geïntroduceerd door differentiële selectie of retentie in een studie. Het omgekeerde is ook waar: zelfs als de selectie en retentie in de studie een eerlijke representatie is van de populatie waaruit de steekproeven zijn getrokken, kan de schatting van de associatie vertekend zijn als de proefpersonen onjuist zijn gecategoriseerd met betrekking tot hun blootstellingsstatus of uitkomst. Deze fouten worden vaak misclassificatie genoemd, en het mechanisme dat deze fouten veroorzaakt kan resulteren in ofwel niet-differentiële ofwel differentiële misclassificatie. Ken Rothman onderscheidt deze als volgt:
onderscheidt deze als volgt:
“Voor blootstellingsmisclassificatie is de misclassificatie niet-differentieel als ze geen verband houdt met het voorkomen of de aanwezigheid van ziekte; als de misclassificatie van blootstelling verschillend is voor mensen met en zonder ziekte, is ze differentieel. Evenzo is de verkeerde classificatie van ziekte niet-differentieel als er geen verband is met de blootstelling; anders is zij differentieel.”
Niet-differentiële verkeerde classificatie van blootstelling
Niet-differentiële verkeerde classificatie betekent dat de frequentie van de fouten ongeveer gelijk is in de groepen die worden vergeleken. Verkeerde classificatie van de blootstellingsstatus is een groter probleem dan verkeerde classificatie van de uitkomst (zoals uitgelegd op pagina 6), maar een studie kan vertekend zijn door verkeerde classificatie van ofwel de blootstellingsstatus, ofwel de uitkomststatus, ofwel beide.
Nondifferentiële verkeerde classificatie van een dichotome blootstelling treedt op wanneer fouten bij de classificatie in dezelfde mate voorkomen, ongeacht de uitkomst. Niet-differentiële onjuiste classificatie van blootstelling is een veel algemener probleem dan differentiële onjuiste classificatie (waarbij fouten vaker voorkomen in een van de onderzoeksgroepen). Onderstaande figuur illustreert een hypothetisch onderzoek waarin alle proefpersonen correct zijn geclassificeerd met betrekking tot het resultaat, maar sommige van de blootgestelde proefpersonen in elke uitkomstgroep ten onrechte als ‘niet-blootgesteld’ zijn geclassificeerd.
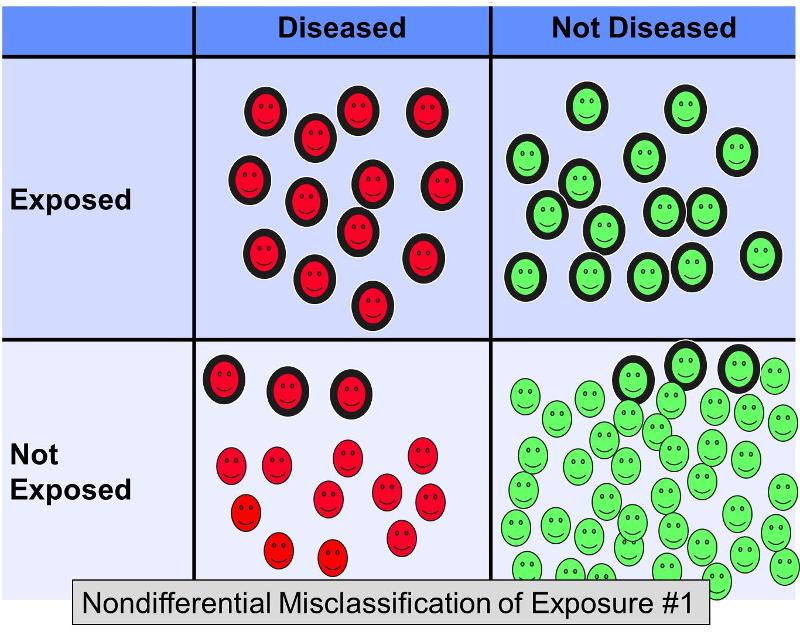
Voorstel dat een case-controlstudie is uitgevoerd om het verband tussen een vetrijk dieet en coronaire hartziekte te onderzoeken. Proefpersonen met hartaandoeningen en controles zonder hartaandoeningen zouden kunnen worden gerekruteerd en gevraagd vragenlijsten over hun voedingsgewoonten in te vullen om hen te categoriseren als mensen met of zonder vetrijke voeding. Het is moeilijk om aan de hand van vragenlijsten het vetgehalte in de voeding nauwkeurig te bepalen, dus het zou niet verbazen als er fouten zouden optreden bij de classificatie van de blootstelling. Het is echter waarschijnlijk dat in dit scenario de verkeerde indeling met min of meer gelijke frequentie zou voorkomen, ongeacht de uiteindelijke ziektestatus. Niet-differentiële verkeerde classificatie van een dichotome blootstelling neigt altijd naar de nul. Met andere woorden, als er een associatie is, is deze geneigd te minimaliseren, ongeacht of het een positieve of negatieve associatie is.
De bovenstaande figuur toont een scenario waarin de ziektestatus correct wordt geclassificeerd, maar een deel van de blootgestelde personen ten onrechte als niet-blootgesteld wordt geclassificeerd. Dit zou resulteren in een vertekening in de richting van de nul. Rothman geeft een hypothetisch voorbeeld waarin de werkelijke odds ratio voor het verband tussen een vetrijk dieet en coronaire hartziekten 5,0 is, maar als ongeveer 20% van de blootgestelde personen in beide ziektetoestanden verkeerd wordt ingedeeld als “niet blootgesteld”, zou de vertekende schatting een odds ratio van, zeg, 2,4 kunnen opleveren. Met andere woorden, het resulteerde in een vertekening in de richting van de nul.
Bedenk nu eens wat er in hetzelfde voorbeeld zou gebeuren als 20% van de blootgestelde personen in beide uitkomstgroepen verkeerd zou zijn geclassificeerd als ‘niet blootgesteld’, EN 20% van de niet-blootgestelde personen in beide groepen verkeerd zou zijn geclassificeerd als ‘blootgesteld’ – met andere woorden een scenario dat er ongeveer zo uit zou zien:
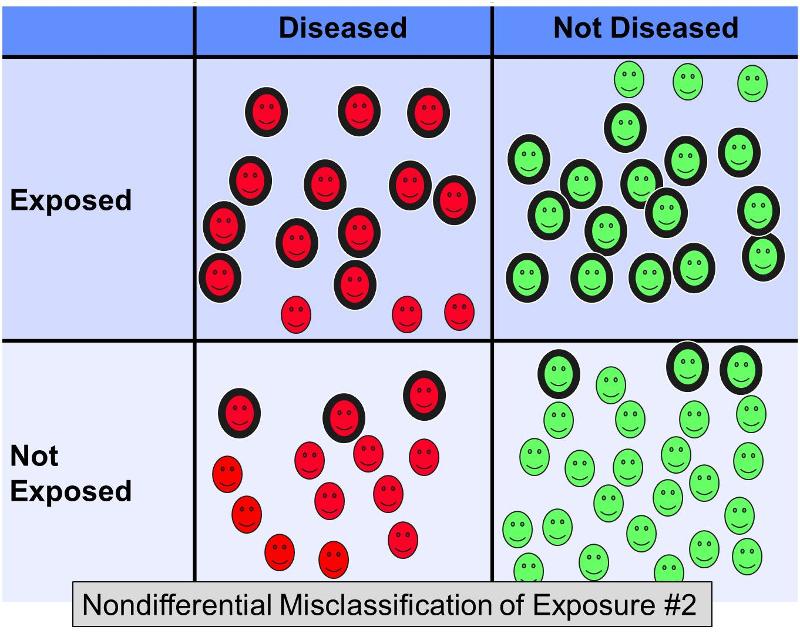
Deze extra niet-differentiële misclassificatie zou resulteren in een nog ernstiger vertekening in de richting van de nul, waardoor de odds ratio misschien 2,0 zou bedragen.
Merk op dat als er meerdere blootstellingscategorieën zijn, d.w.z. als de blootstelling niet dichotomisch is, kan nondifferentiële misclassificatie de schatting ofwel in de richting van de nul ofwel in de richting van de nul vertekenen, afhankelijk van de categorieën waarin de proefpersonen verkeerd zijn ingedeeld.
Mechanismen voor nondifferentiële misclassificatie
Nondifferentiële misclassificatie kan op een aantal manieren optreden. Dossiers kunnen onvolledig zijn, bijvoorbeeld een medisch dossier waarin geen van de zorgverleners zich herinnert naar tabaksgebruik te vragen. Er kunnen fouten zijn bij het registreren of interpreteren van informatie in dossiers, of er kunnen fouten zijn bij het toekennen van codes aan ziektediagnoses door administratief personeel dat niet bekend is met het ziekenhuisverloop, de diagnose en de behandeling van een patiënt. Proefpersonen die vragenlijsten invullen of worden geïnterviewd, kunnen moeite hebben zich vroegere blootstellingen te herinneren. Merk op dat indien de moeilijkheden in het herinneren van vroegere blootstellingen in dezelfde mate voorkomen in beide groepen die worden vergeleken, er sprake is van niet-differentiële misclassificatie, die een vertekening in de richting van de nul zal geven. Als de ene uitkomstgroep in een case-controlstudie zich echter beter herinnert dan de andere, is er sprake van differentiële misclassificatie die “recall bias” wordt genoemd. Recall bias wordt hieronder beschreven onder differentiële misclassificatie van blootstelling.
terug naar boven | vorige pagina | volgende pagina