D’après la section précédente, il devrait être clair que, même si la catégorisation des sujets concernant l’exposition et le résultat est parfaitement exacte, un biais peut être introduit par la sélection différentielle ou la rétention dans une étude. L’inverse est également vrai : même si la sélection et la rétention dans l’étude sont une représentation équitable de la population dont les échantillons ont été tirés, l’estimation de l’association peut être biaisée si les sujets sont incorrectement catégorisés en ce qui concerne leur statut d’exposition ou leur résultat. Ces erreurs sont souvent appelées erreurs de classification, et le mécanisme qui produit ces erreurs peut entraîner une erreur de classification non différentielle ou différentielle. Ken Rothman les distingue comme suit:
les distingue comme suit:
« Pour une erreur de classification de l’exposition, l’erreur de classification est non différentielle si elle n’est pas liée à l’apparition ou à la présence de la maladie ; si l’erreur de classification de l’exposition est différente pour les personnes avec et sans maladie, elle est différentielle. De même, la mauvaise classification de la maladie est non différentielle si elle n’est pas liée à l’exposition ; sinon, elle est différentielle. »
Mauvaise classification non différentielle de l’exposition
La mauvaise classification non différentielle signifie que la fréquence des erreurs est approximativement la même dans les groupes comparés. La mauvaise classification du statut d’exposition est plus problématique que la mauvaise classification du résultat (comme expliqué à la page 6), mais une étude peut être biaisée par une mauvaise classification soit du statut d’exposition, soit du statut du résultat, soit des deux.
La mauvaise classification non différentielle d’une exposition dichotomique se produit lorsque les erreurs de classification se produisent au même degré, quel que soit le résultat. La mauvaise classification non différentielle de l’exposition est un problème beaucoup plus répandu que la mauvaise classification différentielle (dans laquelle les erreurs se produisent avec une plus grande fréquence dans l’un des groupes d’étude). La figure ci-dessous illustre une étude hypothétique dans laquelle tous les sujets sont correctement classés par rapport au résultat, mais certains des sujets exposés dans chaque groupe de résultats ont été incorrectement classés comme » non exposés « .’
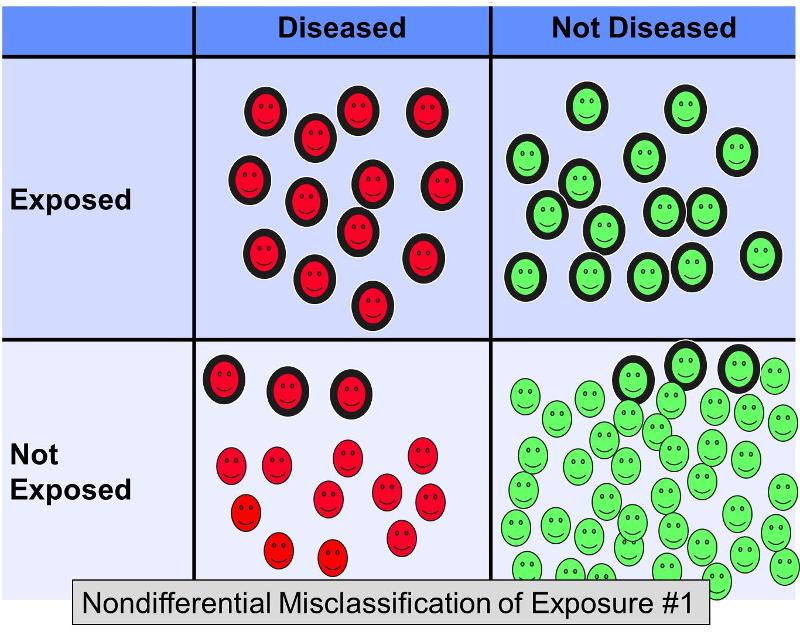
Supposons qu’une étude cas-témoins ait été menée pour examiner l’association entre un régime riche en graisses et une maladie coronarienne. On pourrait recruter des sujets atteints de maladies cardiaques et des témoins sans maladie cardiaque et leur demander de remplir des questionnaires sur leurs habitudes alimentaires afin de les classer dans la catégorie des régimes à forte teneur en graisses ou non. Il est difficile d’évaluer avec précision la teneur en graisses des régimes alimentaires à partir de questionnaires, il ne serait donc pas surprenant qu’il y ait des erreurs dans la classification de l’exposition. Cependant, il est probable que dans ce scénario, les erreurs de classification se produisent avec une fréquence plus ou moins égale, quel que soit le statut de la maladie. La classification erronée non différentielle d’une exposition dichotomique penche toujours vers la valeur nulle. En d’autres termes, s’il existe une association, elle tend à la minimiser, qu’il s’agisse d’une association positive ou négative.
La figure ci-dessus décrit un scénario dans lequel le statut de la maladie est correctement classé, mais certains des sujets exposés sont incorrectement classés comme non exposés. Il en résulterait un biais vers la valeur nulle. Rothman donne un exemple hypothétique dans lequel le véritable rapport de cotes pour l’association entre un régime riche en graisses et les maladies coronariennes est de 5,0, mais si environ 20 % des sujets exposés étaient classés à tort comme » non exposés » dans les deux groupes de maladies, l’estimation biaisée pourrait donner un rapport de cotes de, disons, 2,4. En d’autres termes, cela a entraîné un biais vers la valeur nulle.
Cependant, considérez maintenant ce qui se passerait dans le même exemple si 20 % des sujets exposés étaient classés à tort comme ‘non exposés’ dans les deux groupes de résultats, ET si 20 % des sujets non exposés étaient classés à tort comme ‘exposés’ dans les deux groupes – en d’autres termes, un scénario qui ressemblait à quelque chose comme ceci :
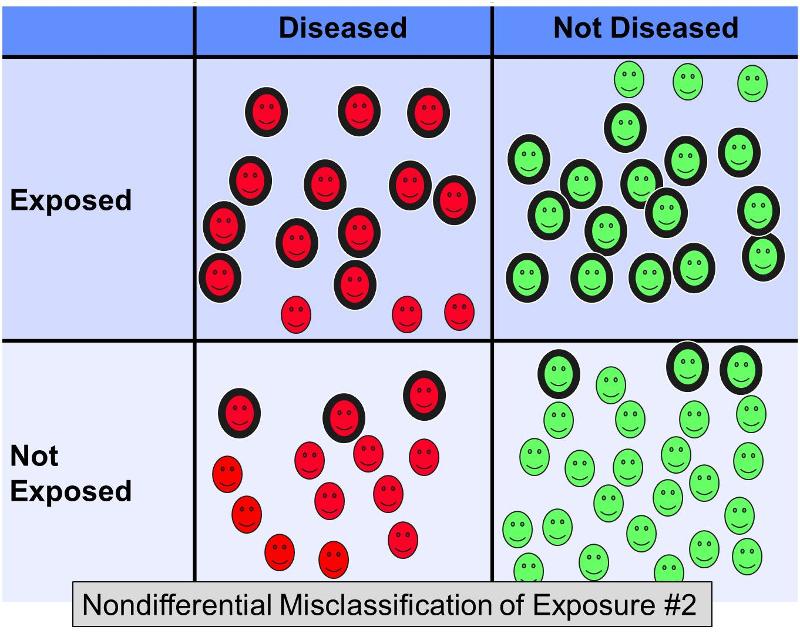
Cette erreur de classification non différentielle supplémentaire entraînerait un biais encore plus important vers la valeur nulle, donnant un odds ratio de peut-être 2,0.
Notez que S’il existe plusieurs catégories d’exposition, c’est-à-dire. si l’exposition n’est pas dichotomique, alors l’erreur de classification non différentielle peut biaiser l’estimation soit vers la valeur nulle, soit en s’en éloignant, selon les catégories dans lesquelles les sujets sont mal classés.
Mécanismes d’erreur de classification non différentielle
L’erreur de classification non différentielle peut se produire de plusieurs façons. Les dossiers peuvent être incomplets, par exemple, un dossier médical dans lequel aucun des travailleurs de la santé ne se souvient de poser des questions sur le tabagisme. Il peut y avoir des erreurs dans l’enregistrement ou l’interprétation des informations contenues dans les dossiers, ou des erreurs dans l’attribution des codes aux diagnostics de maladie par des employés de bureau qui ne connaissent pas bien le parcours hospitalier, le diagnostic et le traitement d’un patient. Les sujets qui remplissent les questionnaires ou qui sont interrogés peuvent avoir des difficultés à se souvenir des expositions passées. Notez que si la difficulté à se souvenir des expositions passées se produit dans la même mesure dans les deux groupes comparés, alors il y a une erreur de classification non différentielle, qui penchera vers la valeur nulle. Cependant, si un groupe de résultats dans une étude cas-témoins se souvient mieux que l’autre, il y a alors une erreur de classification différentielle appelée « biais de rappel ». Le biais de rappel est décrit ci-dessous dans le cadre de l’erreur de classification différentielle de l’exposition.
Retour en haut | page précédente | page suivante