Z poprzedniej części powinno być jasne, że nawet jeśli kategoryzacja badanych w odniesieniu do ekspozycji i wyniku jest idealnie dokładna, bias może być wprowadzony przez selekcję różnicową lub zatrzymanie w badaniu. Nawet jeśli dobór i zatrzymanie w badaniu jest uczciwą reprezentacją populacji, z której pobrano próbki, oszacowanie asocjacji może być tendencyjne, jeśli uczestnicy są nieprawidłowo skategoryzowani w odniesieniu do ich statusu ekspozycji lub wyniku. Błędy te są często określane jako błędna klasyfikacja, a mechanizm, który powoduje te błędy, może skutkować albo nieróżnicującą, albo różnicującą błędną klasyfikacją. Ken Rothman rozróżnia je w następujący sposób:
rozróżnia je w następujący sposób:
„W przypadku błędnej klasyfikacji ekspozycji, błędna klasyfikacja jest nieróżnicująca, jeśli nie jest związana z wystąpieniem lub obecnością choroby; jeśli błędna klasyfikacja ekspozycji jest różna dla osób z chorobą i bez choroby, jest różnicująca. Podobnie, błędna klasyfikacja choroby jest nieróżnicująca, jeśli jest niezwiązana z ekspozycją; w przeciwnym razie jest różnicująca.”
Nieróżnicująca błędna klasyfikacja ekspozycji
Nieróżnicująca błędna klasyfikacja oznacza, że częstość błędów jest w przybliżeniu taka sama w porównywanych grupach. Błędna klasyfikacja statusu ekspozycji jest większym problemem niż błędna klasyfikacja wyniku (jak wyjaśniono na stronie 6), ale badanie może być stronnicze z powodu błędnej klasyfikacji albo statusu ekspozycji, albo statusu wyniku, albo obu.
Niezróżnicowana błędna klasyfikacja dychotomicznej ekspozycji występuje wtedy, gdy błędy w klasyfikacji występują w tym samym stopniu niezależnie od wyniku. Nieróżnicująca błędna klasyfikacja ekspozycji jest znacznie bardziej rozpowszechnionym problemem niż różnicująca błędna klasyfikacja (w której błędy występują z większą częstością w jednej z badanych grup). Poniższy rysunek ilustruje hipotetyczne badanie, w którym wszyscy badani są prawidłowo sklasyfikowani w odniesieniu do wyniku, ale niektórzy z eksponowanych uczestników w każdej grupie wyników zostali nieprawidłowo sklasyfikowani jako 'nieeksponowani’.
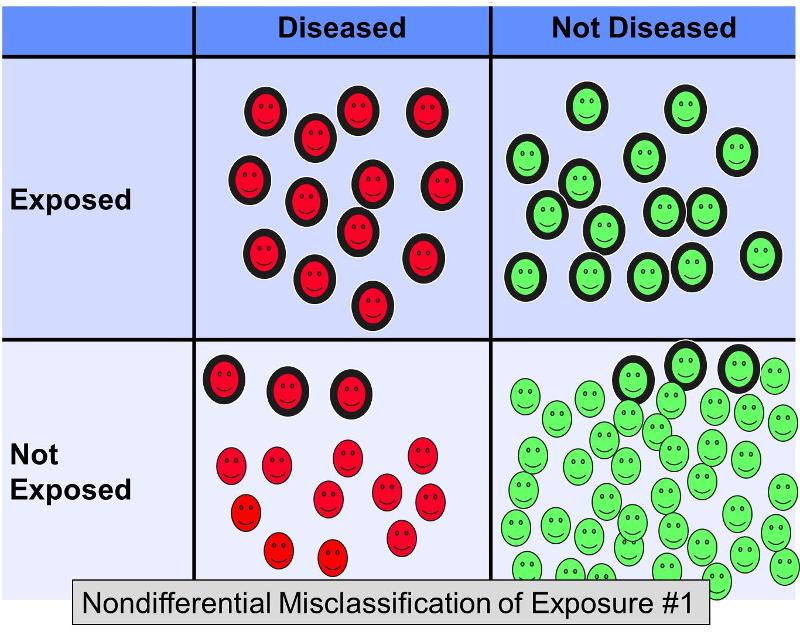
Załóżmy, że przeprowadzono badanie case-control w celu zbadania związku między dietą wysokotłuszczową a chorobą wieńcową. Osoby z chorobą serca i osoby kontrolne bez choroby serca mogłyby być rekrutowane i proszone o wypełnienie kwestionariuszy dotyczących ich nawyków żywieniowych w celu zaklasyfikowania ich jako osoby stosujące dietę o wysokiej zawartości tłuszczu lub nie. Trudno jest ocenić zawartość tłuszczu w diecie dokładnie z kwestionariuszy, więc nie byłoby zaskakujące, jeśli były błędy w klasyfikacji ekspozycji. Jest jednak prawdopodobne, że w tym scenariuszu błędna klasyfikacja wystąpiłaby z mniej więcej równą częstością, niezależnie od ostatecznego stanu choroby. Nieróżnicująca błędna klasyfikacja dychotomicznej ekspozycji zawsze skłania się ku zeru. Innymi słowy, jeśli istnieje skojarzenie, ma tendencję do minimalizowania go niezależnie od tego, czy jest to pozytywne czy negatywne skojarzenie.
Powyższy rysunek przedstawia scenariusz, w którym status choroby jest prawidłowo sklasyfikowany, ale niektóre z narażonych przedmiotów są nieprawidłowo sklasyfikowane jako nienarażone. Spowodowałoby to tendencyjność w kierunku zerowym. Rothman podaje hipotetyczny przykład, w którym prawdziwy iloraz szans dla związku między dietą wysokotłuszczową a chorobą wieńcową wynosi 5,0, ale jeśli około 20% narażonych podmiotów zostało błędnie sklasyfikowanych jako „nie narażone” w obu grupach chorobowych, tendencyjne oszacowanie może dać iloraz szans, powiedzmy, 2,4. Innymi słowy, spowodowało to tendencyjność w kierunku zera.
Rozważmy jednak teraz, co by się stało w tym samym przykładzie, gdyby 20% osób narażonych zostało błędnie zaklasyfikowanych jako „nienarażone” w obu grupach wyników, ORAZ 20% osób nienarażonych zostało błędnie zaklasyfikowanych jako „narażone” w obu grupach – innymi słowy, scenariusz wyglądałby mniej więcej tak:
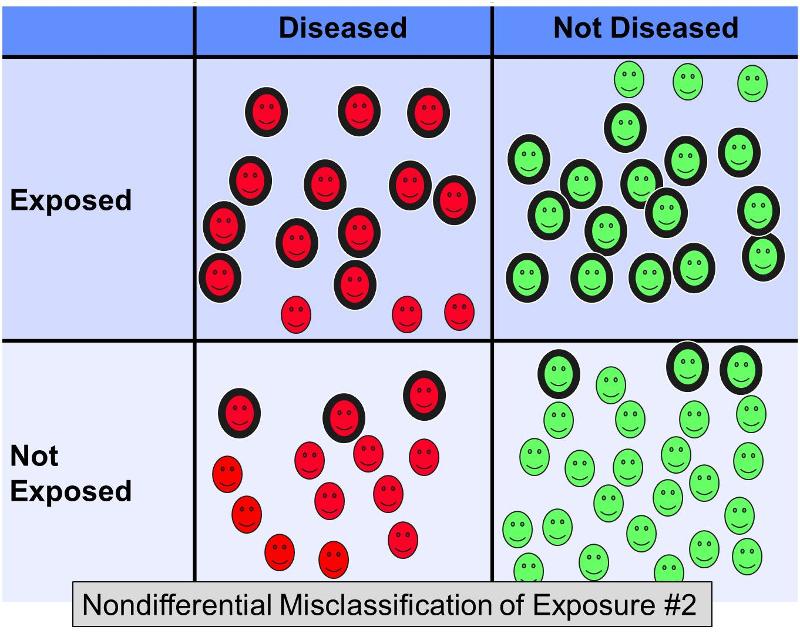
Ta dodatkowa nieróżnicująca błędna klasyfikacja spowodowałaby jeszcze poważniejszą tendencyjność w kierunku zera, dając iloraz szans być może 2,0.
Zauważ, że jeśli istnieje wiele kategorii ekspozycji, tj. jeśli ekspozycja nie jest dychotomiczna, wówczas nieróżnicująca błędna klasyfikacja może pochylić szacunek albo w kierunku zera, albo z dala od niego, w zależności od kategorii, do których uczestnicy są błędnie zaklasyfikowani.
Mechanizmy nieróżnicującej błędnej klasyfikacji
Nieróżnicująca błędna klasyfikacja może wystąpić na wiele sposobów. Dokumentacja może być niekompletna, np. dokumentacja medyczna, w której żaden z pracowników opieki zdrowotnej nie pamięta, aby zapytać o używanie tytoniu. Mogą wystąpić błędy w zapisie lub interpretacji informacji w dokumentacji lub mogą wystąpić błędy w przypisywaniu kodów do rozpoznań chorób przez pracowników biurowych, którzy nie są zaznajomieni z przebiegiem hospitalizacji, rozpoznaniem i leczeniem pacjenta. Osoby wypełniające kwestionariusze lub przeprowadzające wywiady mogą mieć trudności z przypomnieniem sobie przebytych ekspozycji. Zauważ, że jeśli trudności w zapamiętywaniu przeszłych ekspozycji występują w tym samym stopniu w obu porównywanych grupach, wtedy istnieje nieróżnicująca błędna klasyfikacja, która będzie skłaniać się ku zeru. Jednakże, jeśli jedna grupa wyników w badaniu case-control pamięta lepiej niż druga, wtedy mamy do czynienia z różnicowym błędem klasyfikacji, który nazywany jest „recall bias”. Skłonność do przypominania sobie jest opisana poniżej w części dotyczącej różnicowej błędnej klasyfikacji ekspozycji.
powrót do góry | poprzednia strona | następna strona
.