Din secțiunea anterioară ar trebui să fie clar că, chiar dacă clasificarea subiecților în ceea ce privește expunerea și rezultatul este perfect exactă, se poate introduce un bias prin selecție diferențială sau retenție într-un studiu. Inversul este, de asemenea, adevărat: chiar dacă selecția și reținerea în studiu reprezintă în mod corect populația din care au fost extrase eșantioanele, estimarea asocierii poate fi distorsionată dacă subiecții sunt incorect categorisiți în ceea ce privește starea de expunere sau rezultatul. Aceste erori sunt adesea denumite erori de clasificare, iar mecanismul care produce aceste erori poate avea ca rezultat fie o clasificare greșită nediferențială, fie una diferențială. Ken Rothman le distinge după cum urmează:
le distinge după cum urmează:
„Pentru clasificarea eronată a expunerii, clasificarea eronată este nediferențială dacă nu are legătură cu apariția sau prezența bolii; dacă clasificarea eronată a expunerii este diferită pentru cei cu și fără boală, aceasta este diferențială. În mod similar, clasificarea eronată a bolii este nediferențială dacă nu are legătură cu expunerea; în caz contrar, este diferențială.”
Clasificarea eronată nediferențială a expunerii
Clasificarea eronată nediferențială înseamnă că frecvența erorilor este aproximativ aceeași în grupurile care sunt comparate. Clasificarea eronată a stării de expunere este o problemă mai mare decât clasificarea eronată a rezultatului (așa cum se explică la pagina 6), dar un studiu poate fi distorsionat de clasificarea eronată fie a stării de expunere, fie a stării de rezultat, fie a ambelor.
Clasificarea eronată nediferențială a unei expuneri dihotomice apare atunci când erorile de clasificare apar în același grad, indiferent de rezultat. Clasificarea eronată nediferențială a expunerii este o problemă mult mai răspândită decât clasificarea eronată diferențială (în care erorile apar cu o frecvență mai mare în unul dintre grupurile de studiu). Figura de mai jos ilustrează un studiu ipotetic în care toți subiecții sunt clasificați corect în ceea ce privește rezultatul, dar unii dintre subiecții expuși din fiecare grup de rezultate au fost clasificați în mod incorect ca „neexpuși”.’
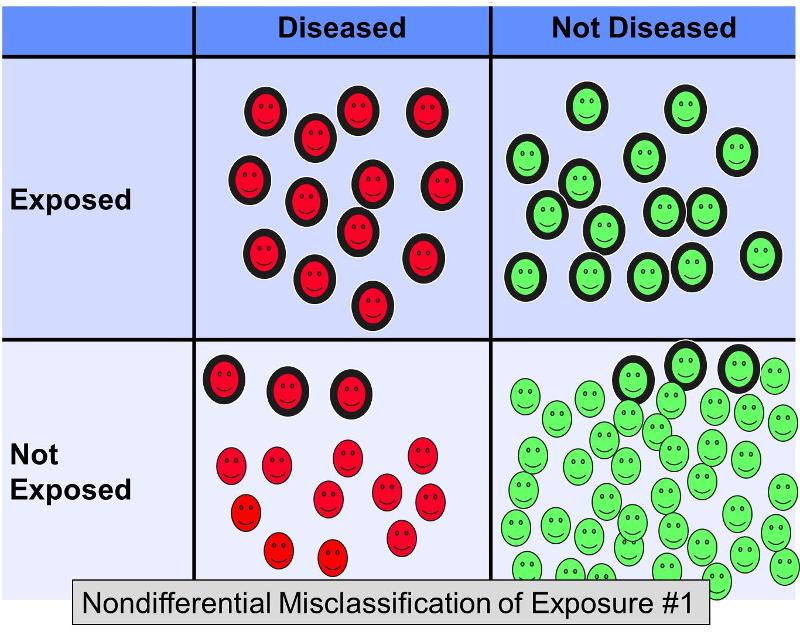
Să presupunem că a fost efectuat un studiu caz-control pentru a examina asocierea dintre o dietă bogată în grăsimi și boala coronariană. S-ar putea recruta subiecți cu afecțiuni cardiace și controale fără afecțiuni cardiace și li s-ar putea cere să completeze chestionare despre obiceiurile lor alimentare pentru a-i clasifica ca având sau nu diete cu conținut ridicat de grăsimi. Este dificil de evaluat cu exactitate conținutul de grăsimi din alimentație pe baza chestionarelor, astfel încât nu ar fi surprinzător dacă ar exista erori de clasificare a expunerii. Cu toate acestea, este probabil că, în acest scenariu, clasificarea eronată ar avea loc cu o frecvență mai mult sau mai puțin egală, indiferent de statutul final al bolii. Clasificarea eronată nediferențiată a unei expuneri dihotomice predispune întotdeauna spre nul. Cu alte cuvinte, dacă există o asociere, aceasta tinde să o minimizeze, indiferent dacă este o asociere pozitivă sau negativă.
Figura de mai sus descrie un scenariu în care statutul bolii este clasificat corect, dar unii dintre subiecții expuși sunt clasificați în mod incorect ca neexpuși. Acest lucru ar avea ca rezultat o prejudecată spre nul. Rothman oferă un exemplu ipotetic în care adevăratul odds ratio pentru asocierea dintre o dietă bogată în grăsimi și bolile coronariene este de 5,0, dar dacă aproximativ 20% dintre subiecții expuși au fost clasificați greșit ca „neexpuși” în ambele grupuri de boli, estimarea părtinitoare ar putea da un odds ratio de, să zicem, 2,4. Cu alte cuvinte, a avut ca rezultat o distorsiune spre nul.
Cu toate acestea, analizați acum ce s-ar întâmpla în același exemplu dacă 20% dintre subiecții expuși ar fi fost clasificați greșit ca „neexpuși” în ambele grupuri de rezultate, ȘI 20% dintre subiecții neexpuși ar fi fost clasificați greșit ca „expuși” în ambele grupuri – cu alte cuvinte, un scenariu care ar arăta cam așa:
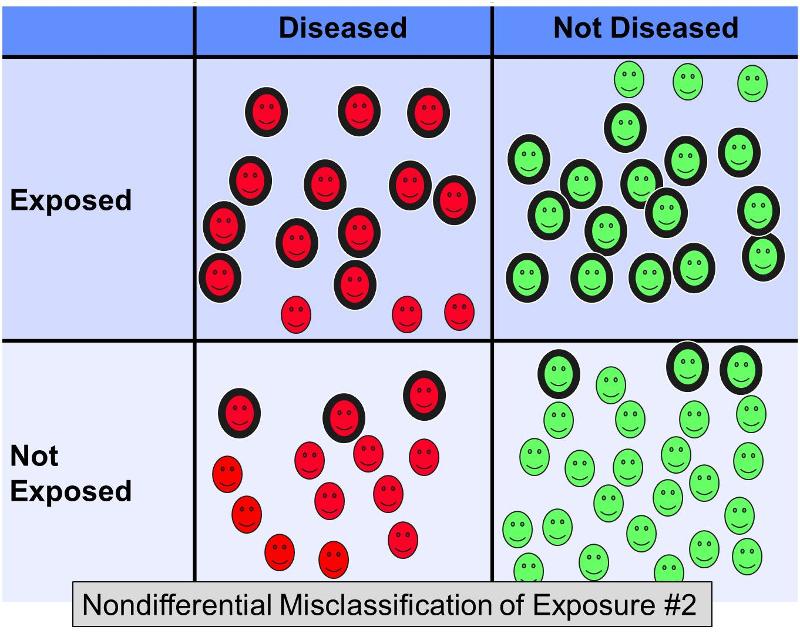
Această clasificare eronată nediferențială suplimentară ar duce la o prejudecată și mai severă spre nul, ceea ce ar da un odds ratio de poate 2,0.
Rețineți că Dacă există mai multe categorii de expunere, de ex. dacă expunerea nu este dihotomică, atunci clasificarea eronată nediferențială poate devia estimarea fie spre nul, fie departe de acesta, în funcție de categoriile în care subiecții sunt clasificați eronat.
Mecanisme de clasificare eronată nediferențială
Clasificarea eronată nediferențială poate apărea în mai multe moduri. Înregistrările pot fi incomplete, de exemplu, un dosar medical în care niciunul dintre asistenții medicali nu își amintește să întrebe despre consumul de tutun. Pot exista erori de înregistrare sau de interpretare a informațiilor din fișe sau pot exista erori în atribuirea codurilor la diagnosticele de boală de către lucrătorii de birou care nu sunt familiarizați cu evoluția, diagnosticul și tratamentul unui pacient în spital. Subiecții care completează chestionare sau sunt intervievați pot avea dificultăți în a-și aminti expunerile anterioare. Rețineți că, în cazul în care dificultatea de a-și aminti expunerile trecute se manifestă în aceeași măsură în ambele grupuri comparate, atunci există o clasificare greșită nediferențială, ceea ce va influența negativitatea. Cu toate acestea, dacă un grup de rezultate într-un studiu caz-control își amintește mai bine decât celălalt, atunci există o clasificare greșită diferențială care se numește „prejudecată de reamintire”. Biasarea de reamintire este descrisă mai jos la capitolul clasificarea eronată diferențială a expunerii.
întoarceți-vă la începutul paginii | pagina anterioară | pagina următoare