Az előző szakaszból világossá kell válnia, hogy még akkor is, ha a vizsgálati alanyok kategorizálása az expozíció és a kimenetel tekintetében tökéletesen pontos, a vizsgálatban bevezethető torzítás a differenciált szelekció vagy a megtartás. A fordítottja is igaz: még ha a vizsgálatba való kiválasztás és visszatartás tisztességesen reprezentálja is azt a populációt, amelyből a mintákat vették, az asszociáció becslése torz lehet, ha a vizsgálati alanyokat expozíciós státuszuk vagy kimenetelük tekintetében helytelenül kategorizálják. Ezeket a hibákat gyakran téves besorolásnak nevezik, és az ezeket a hibákat előidéző mechanizmus nem differenciális vagy differenciális téves besorolást eredményezhet. Ken Rothman a következőképpen különbözteti meg ezeket:
a következőképpen különbözteti meg ezeket:
“Az expozíció téves besorolása esetén a téves besorolás nem differenciális, ha nincs összefüggésben a betegség megjelenésével vagy jelenlétével; ha az expozíció téves besorolása a betegséggel és a betegség nélkül élők esetében eltérő, akkor differenciális. Hasonlóképpen, a betegség téves besorolása nem differenciális, ha nincs összefüggésben az expozícióval; ellenkező esetben differenciális.”
Az expozíció nem differenciális téves besorolása
A nem differenciális téves besorolás azt jelenti, hogy a hibák gyakorisága megközelítőleg azonos az összehasonlított csoportokban. Az expozíciós státusz téves besorolása nagyobb problémát jelent, mint a kimenetel téves besorolása (amint azt a 6. oldalon kifejtettük), de egy vizsgálatot torzíthat akár az expozíciós státusz, akár a kimeneti státusz, akár mindkettő téves besorolása.
A dichotóm expozíció nem differenciális téves besorolása akkor fordul elő, ha a besorolási hibák a kimenettől függetlenül azonos mértékben fordulnak elő. Az expozíció nem differenciális téves besorolása sokkal elterjedtebb probléma, mint a differenciális téves besorolás (amikor a hibák nagyobb gyakorisággal fordulnak elő az egyik vizsgálati csoportban). Az alábbi ábra egy olyan hipotetikus vizsgálatot szemléltet, amelyben minden vizsgálati alanyt helyesen soroltak be a kimenetel tekintetében, de az egyes kimeneti csoportokban az expozíciónak kitett vizsgálati alanyok közül néhányat tévesen “nem exponáltnak” minősítettek.’
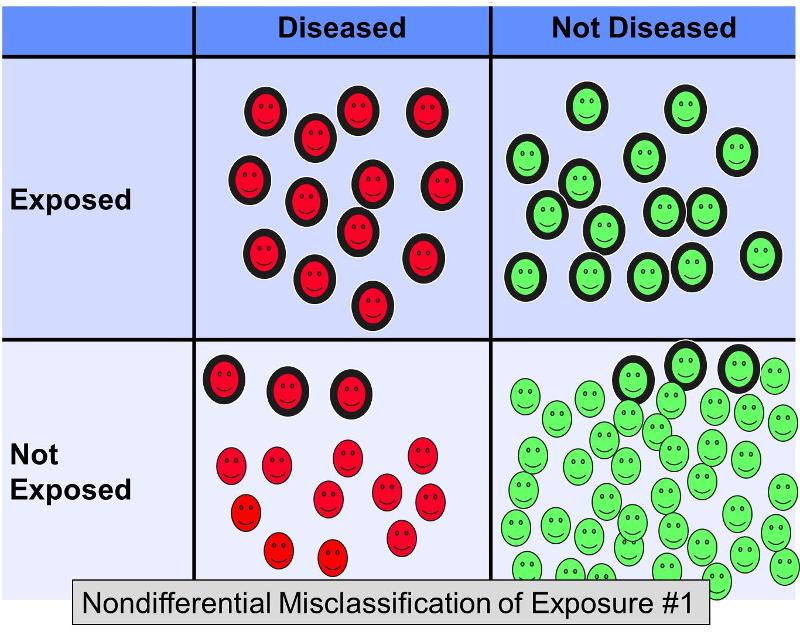
Tegyük fel, hogy egy eset-kontroll vizsgálatot végeztek a magas zsírtartalmú étrend és a koszorúér-betegség közötti kapcsolat vizsgálatára. Szívbetegségben szenvedő alanyokat és szívbetegséggel nem rendelkező kontrollszemélyeket toborozhatnának, és megkérhetnék őket, hogy töltsenek ki kérdőíveket az étkezési szokásaikról, hogy besorolhassák őket a magas zsírtartalmú vagy nem magas zsírtartalmú étrenddel rendelkezők közé. Az étrend zsírtartalmát nehéz pontosan felmérni a kérdőívek alapján, ezért nem lenne meglepő, ha az expozíció besorolása hibás lenne. Valószínű azonban, hogy ebben a forgatókönyvben a téves besorolás többé-kevésbé azonos gyakorisággal fordulna elő, függetlenül az esetleges betegségstátusztól. A dichotóm expozíció nem differenciális téves besorolása mindig a nulla felé torzít. Más szóval, ha van asszociáció, akkor hajlamos azt minimalizálni, függetlenül attól, hogy pozitív vagy negatív asszociációról van-e szó.
A fenti ábra egy olyan forgatókönyvet ábrázol, amelyben a betegségstátuszt helyesen osztályozzák, de az expozíciónak kitett alanyok egy részét tévesen nem exponáltnak minősítik. Ez torzítást eredményezne a nulla felé. Rothman egy hipotetikus példát ad, amelyben a magas zsírtartalmú étrend és a szívkoszorúér-betegség közötti összefüggés valódi esélyhányadosa 5,0, de ha az expozíciónak kitett alanyok körülbelül 20%-át mindkét betegségcsoportban tévesen “nem expozíciónak” minősítették, akkor a torzított becslés mondjuk 2,4-es esélyhányadost adhat. Más szóval, ez a nullához való torzítást eredményezett.
Most azonban gondoljuk meg, mi történne ugyanebben a példában, ha az expozíciónak kitett alanyok 20%-át mindkét kimeneti csoportban tévesen “nem expozíciónak” minősítenék, ÉS a nem exponált alanyok 20%-át mindkét csoportban tévesen “expozíciónak” minősítenék – más szóval egy olyan forgatókönyv, amely valahogy így néz ki:
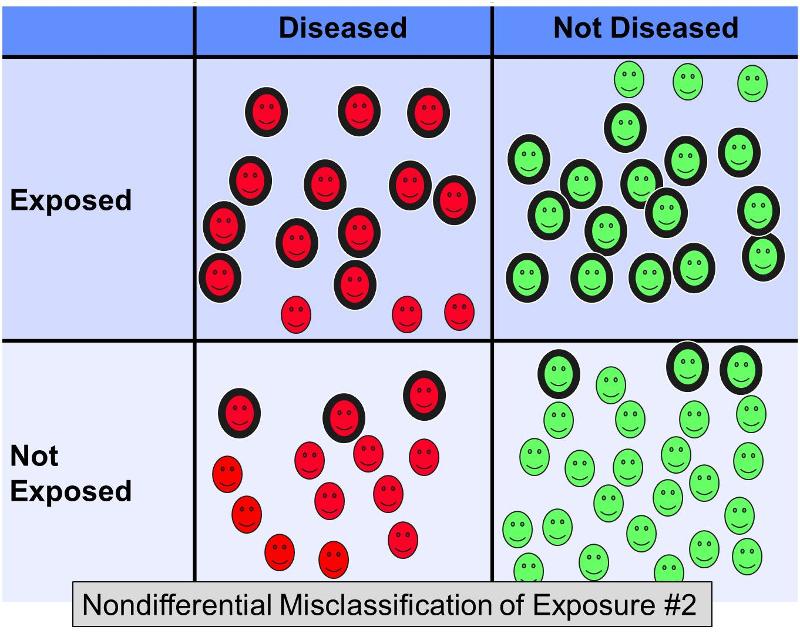
Ez a további nem differenciális téves besorolás még súlyosabb torzítást eredményezne a nulla felé, így az esélyhányados talán 2,0 lenne.
Megjegyezzük, hogy ha több expozíciós kategória van, ill. ha az expozíció nem dichotóm, akkor a nem differenciális téves besorolás a becslést vagy a nulla felé, vagy attól távolabb torzíthatja, attól függően, hogy az alanyokat milyen kategóriákba sorolták tévesen.
A nem differenciális téves besorolás mechanizmusai
A nem differenciális téves besorolás többféleképpen történhet. A feljegyzések hiányosak lehetnek, pl. egy olyan orvosi feljegyzés, amelyben az egészségügyi dolgozók egyike sem emlékszik arra, hogy rákérdezzen a dohányzásra. Előfordulhatnak hibák a nyilvántartásokban szereplő információk rögzítésében vagy értelmezésében, vagy a beteg kórházi kórlefolyását, diagnózisát és kezelését nem ismerő irodai dolgozók hibásan rendelik hozzá a betegségdiagnózisokhoz a kódokat. A kérdőíveket kitöltő vagy megkérdezett alanyok nehezen emlékezhetnek a korábbi expozíciókra. Megjegyzendő, hogy ha a múltbeli expozíciókra való emlékezés nehézségei azonos mértékben fordulnak elő mindkét összehasonlított csoportban, akkor nem differenciális téves besorolásról van szó, ami a nulla érték felé torzít. Ha azonban egy eset-kontroll vizsgálatban az egyik kimeneti csoport jobban emlékszik, mint a másik, akkor differenciális téves besorolásról van szó, amit “visszaemlékezési torzításnak” nevezünk. A visszahívási torzítást az alábbiakban az expozíció differenciális téves besorolása alatt ismertetjük.
vissza a tetejére | előző oldal | következő oldal