Dalla sezione precedente dovrebbe essere chiaro che, anche se la categorizzazione dei soggetti rispetto all’esposizione e all’esito è perfettamente accurata, possono essere introdotti bias di selezione o ritenzione differenziale in uno studio. È vero anche il contrario: anche se la selezione e la ritenzione nello studio sono una giusta rappresentazione della popolazione da cui sono stati prelevati i campioni, la stima dell’associazione può essere distorta se i soggetti sono categorizzati in modo errato rispetto al loro stato di esposizione o all’esito. Questi errori sono spesso chiamati misclassificazione, e il meccanismo che produce questi errori può risultare in una misclassificazione non differenziale o differenziale. Ken Rothman li distingue come segue:
li distingue come segue:
“Per la misclassificazione dell’esposizione, la misclassificazione è non differenziale se non è collegata al verificarsi o alla presenza della malattia; se la misclassificazione dell’esposizione è diversa per quelli con e senza malattia, è differenziale. Allo stesso modo, la misclassificazione della malattia è non differenziale se non è correlata all’esposizione; altrimenti, è differenziale.”
Miscelazione non differenziale dell’esposizione
La misclassificazione non differenziale significa che la frequenza degli errori è approssimativamente la stessa nei gruppi confrontati. L’errata classificazione dello stato di esposizione è un problema maggiore rispetto all’errata classificazione dell’esito (come spiegato a pagina 6), ma uno studio può essere distorto dall’errata classificazione dello stato di esposizione, o dell’esito, o di entrambi.
L’errata classificazione indifferenziale di un’esposizione dicotomica si verifica quando gli errori di classificazione si verificano nella stessa misura indipendentemente dall’esito. L’errore di classificazione non differenziale dell’esposizione è un problema molto più pervasivo dell’errore di classificazione differenziale (in cui gli errori si verificano con maggiore frequenza in uno dei gruppi di studio). La figura sottostante illustra un ipotetico studio in cui tutti i soggetti sono correttamente classificati rispetto all’esito, ma alcuni dei soggetti esposti in ciascun gruppo di esito sono stati erroneamente classificati come “non esposti”.’
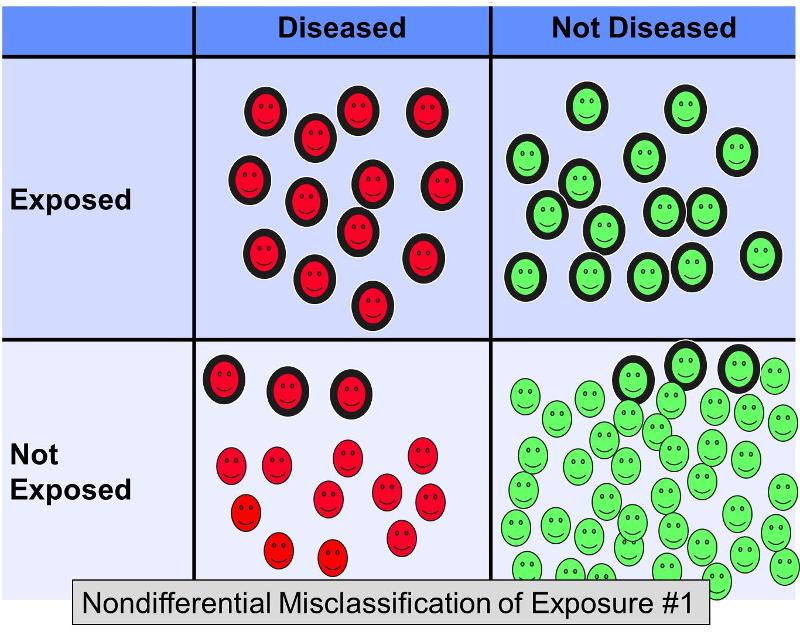
Supponiamo che sia stato condotto uno studio caso-controllo per esaminare l’associazione tra una dieta ricca di grassi e la malattia coronarica. I soggetti con malattie cardiache e i controlli senza malattie cardiache potrebbero essere reclutati e invitati a compilare questionari sulle loro abitudini alimentari per classificarli come aventi una dieta ad alto contenuto di grassi o meno. È difficile valutare accuratamente il contenuto di grassi nella dieta dai questionari, quindi non sarebbe sorprendente se ci fossero errori nella classificazione dell’esposizione. Tuttavia, è probabile che in questo scenario l’errore di classificazione si verifichi con una frequenza più o meno uguale a prescindere dallo stato finale della malattia. L’errata classificazione non differenziale di un’esposizione dicotomica si orienta sempre verso il valore nullo. In altre parole, se c’è un’associazione, tende a minimizzarla indipendentemente dal fatto che si tratti di un’associazione positiva o negativa.
La figura sopra illustra uno scenario in cui lo stato della malattia è classificato correttamente, ma alcuni dei soggetti esposti sono erroneamente classificati come non esposti. Questo comporterebbe una distorsione verso il nullo. Rothman dà un esempio ipotetico in cui il vero odds ratio per l’associazione tra una dieta ricca di grassi e la malattia coronarica è 5.0, ma se circa 20% dei soggetti esposti sono stati erroneamente classificati come ‘non esposti’ in entrambi i gruppi di malattia, la stima distorta potrebbe dare un odds ratio di, diciamo, 2.4. In altre parole, ha provocato una distorsione verso la nullità.
Tuttavia, ora consideriamo cosa accadrebbe nello stesso esempio se il 20% dei soggetti esposti fosse erroneamente classificato come ‘non esposto’ in entrambi i gruppi di risultati, E il 20% dei soggetti non esposti fosse erroneamente classificato come ‘esposto’ in entrambi i gruppi – in altre parole uno scenario simile a questo:
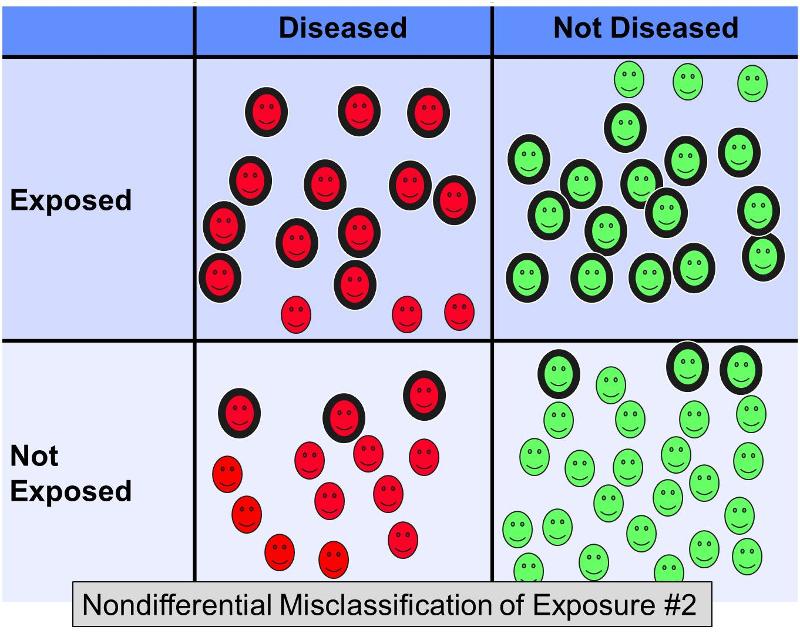
Questo ulteriore errore di classificazione non differenziale comporterebbe una distorsione ancora più grave verso la nullità, dando un odds ratio forse di 2,0.
Nota che se ci sono più categorie di esposizione, cioè se l’esposizione non è dicotomica, allora l’errore di classificazione non differenziale può distorcere la stima sia verso lo zero che lontano da esso, a seconda delle categorie in cui i soggetti vengono classificati in modo errato.
Meccanismi di errore di classificazione non differenziale
L’errore di classificazione non differenziale può verificarsi in diversi modi. Le registrazioni possono essere incomplete, ad esempio una cartella clinica in cui nessuno degli operatori sanitari si ricorda di chiedere informazioni sull’uso del tabacco. Ci possono essere errori nella registrazione o nell’interpretazione delle informazioni nelle registrazioni, o ci possono essere errori nell’assegnazione dei codici alle diagnosi di malattia da parte degli impiegati che non hanno familiarità con il percorso ospedaliero di un paziente, la diagnosi e il trattamento. I soggetti che completano i questionari o vengono intervistati possono avere difficoltà a ricordare le esposizioni passate. Si noti che se la difficoltà a ricordare le esposizioni passate si verifica nella stessa misura in entrambi i gruppi confrontati, allora c’è un errore di classificazione non differenziale, che si orienta verso la soluzione nulla. Tuttavia, se un gruppo di risultato in uno studio caso-controllo ricorda meglio dell’altro, allora c’è un errore di classificazione differenziale che è chiamato “recall bias”. La distorsione da richiamo è descritta di seguito sotto la voce misclassificazione differenziale dell’esposizione.
torna all’inizio | pagina precedente | pagina successiva