Från föregående avsnitt bör det stå klart att även om kategoriseringen av försökspersoner med avseende på exponering och resultat är helt korrekt, kan bias introduceras genom differentiellt urval eller bibehållande i en studie. Det omvända gäller också: även om urvalet och behållandet i studien är en rättvis representation av den population från vilken proverna har dragits, kan uppskattningen av sambandet vara snedvriden om försökspersonerna kategoriseras felaktigt med avseende på deras exponeringsstatus eller utfall. Dessa fel kallas ofta för felklassificering, och den mekanism som ger upphov till dessa fel kan resultera i antingen icke-differentiell eller differentiell felklassificering. Ken Rothman skiljer dessa på följande sätt:
skiljer dessa på följande sätt:
”När det gäller felklassificering av exponering är felklassificeringen icke-differentiell om den inte är relaterad till förekomsten eller närvaron av sjukdom; om felklassificeringen av exponering är annorlunda för dem med och utan sjukdom är den differentiell. På samma sätt är felklassificering av sjukdom icke-differentiell om den inte är relaterad till exponeringen; annars är den differentiell.”
Nondifferentiell felklassificering av exponering
Nondifferentiell felklassificering innebär att felfrekvensen är ungefär densamma i de grupper som jämförs. Felklassificering av exponeringsstatus är ett större problem än felklassificering av utfallet (vilket förklaras på sidan 6), men en studie kan vara snedvriden på grund av felklassificering av antingen exponeringsstatus eller utfallsstatus eller båda.
Nondifferentiell felklassificering av en dikotom exponering inträffar när fel i klassificeringen inträffar i samma utsträckning oavsett utfall. Icke-differentiell felklassificering av exponering är ett mycket mer utbrett problem än differentiell felklassificering (där fel förekommer oftare i en av undersökningsgrupperna). Figuren nedan illustrerar en hypotetisk studie där alla försökspersoner klassificeras korrekt med avseende på resultatet, men några av de exponerade försökspersonerna i varje resultatgrupp klassificeras felaktigt som ”icke-exponerade”.’
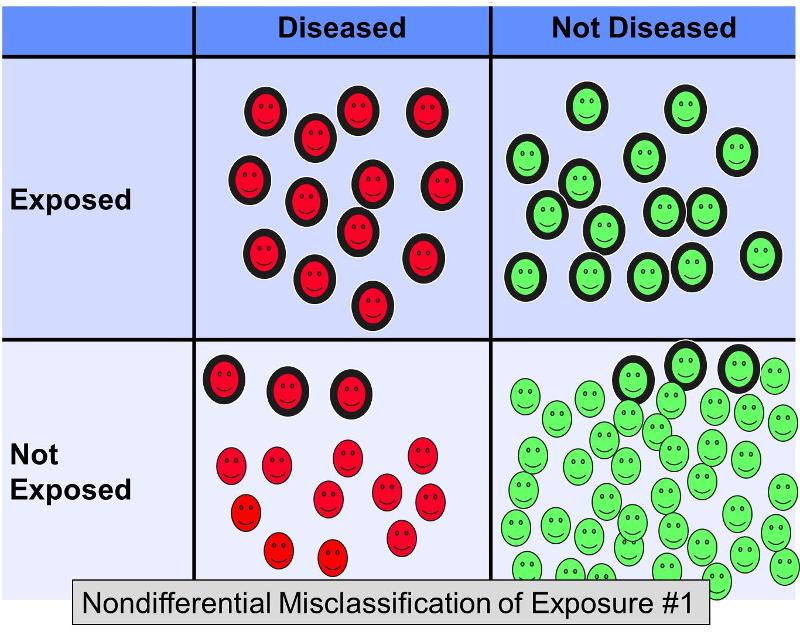
Antag att en fall-kontrollstudie genomfördes för att undersöka sambandet mellan en fettrik kost och kranskärlssjukdom. Försökspersoner med hjärtsjukdom och kontroller utan hjärtsjukdom skulle kunna rekryteras och ombeds fylla i frågeformulär om sina kostvanor för att kunna kategorisera dem som har kost med hög fetthalt eller inte. Det är svårt att bedöma kostens fetthalt exakt utifrån frågeformulär, så det skulle inte vara förvånande om det fanns fel i klassificeringen av exponeringen. Det är dock troligt att felklassificeringen i detta scenario skulle förekomma med mer eller mindre lika stor frekvens oavsett det slutliga sjukdomstillståndet. Icke-differentiell felklassificering av en dikotom exponering ger alltid en förskjutning mot nollalternativet. Med andra ord, om det finns ett samband tenderar det att minimera det oavsett om det är ett positivt eller negativt samband.
Figuren ovan visar ett scenario där sjukdomsstatus klassificeras korrekt, men en del av de exponerade försökspersonerna klassificeras felaktigt som icke-exponerade. Detta skulle resultera i en bias mot nollalternativet. Rothman ger ett hypotetiskt exempel där den sanna oddskvoten för sambandet mellan fettrik kost och kranskärlssjukdom är 5,0, men om cirka 20 % av de exponerade personerna felklassificerades som ”icke-exponerade” i båda sjukdomsgrupperna skulle den snedvridna uppskattningen kunna ge en oddskvot på till exempel 2,4. Med andra ord resulterade det i en snedvridning mot nollalternativet.
Och tänk nu på vad som skulle hända i samma exempel om 20 % av de exponerade försökspersonerna felklassificerades som ”inte exponerade” i båda utfallsgrupperna, OCH 20 % av de icke-exponerade försökspersonerna felklassificerades som ”exponerade” i båda grupperna – med andra ord ett scenario som såg ut ungefär så här:
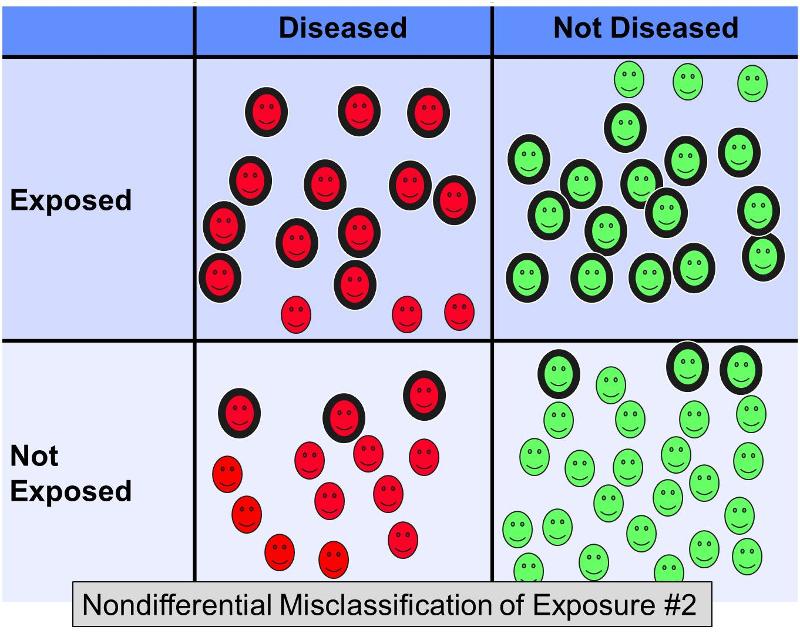
Denna ytterligare icke-differentiella felklassificering skulle resultera i en ännu allvarligare bias mot noll, vilket skulle ge en oddskvot på kanske 2,0.
Notera att Om det finns flera exponeringskategorier, dvs. om exponeringen inte är dikotomisk, så kan icke-differentiell felklassificering snedvrida skattningen antingen mot nollvärdet eller bort från det, beroende på vilka kategorier som försökspersonerna felklassificeras i.
Mekanismer för icke-differentiell felklassificering
Den icke-differentiella felklassificeringen kan inträffa på ett antal olika sätt. Journaler kan vara ofullständiga, t.ex. en medicinsk journal där ingen av vårdpersonalen kommer ihåg att fråga om tobaksbruk. Det kan förekomma fel i registreringen eller tolkningen av informationen i journalerna, eller det kan förekomma fel i tilldelningen av koder till sjukdomsdiagnoser av kontorspersonal som inte är bekant med patientens sjukhusförlopp, diagnos och behandling. Personer som fyller i frågeformulär eller intervjuas kan ha svårt att komma ihåg tidigare exponeringar. Observera att om svårigheten att komma ihåg tidigare exponeringar förekommer i samma utsträckning i båda de jämförda grupperna finns det en icke-differentiell felklassificering, vilket kommer att leda till en snedvridning i riktning mot nollalternativet. Men om den ena resultatgruppen i en fall-kontrollstudie minns bättre än den andra, finns det en differentiell felklassificering som kallas ”minnesbias”. Recall bias beskrivs nedan under differentiell felklassificering av exponering.
Tillbaka till början | föregående sida | nästa sida