Aus dem vorangegangenen Abschnitt sollte deutlich werden, dass selbst bei einer vollkommen korrekten Kategorisierung der Probanden hinsichtlich der Exposition und des Ergebnisses eine Verzerrung durch unterschiedliche Auswahl oder Beibehaltung in einer Studie entstehen kann. Das Umgekehrte gilt ebenfalls: Selbst wenn die Auswahl und der Verbleib in der Studie eine faire Repräsentation der Population ist, aus der die Stichproben gezogen wurden, kann die Schätzung der Assoziation verzerrt sein, wenn die Probanden in Bezug auf ihren Expositionsstatus oder ihr Ergebnis falsch kategorisiert wurden. Diese Fehler werden häufig als Fehlklassifikation bezeichnet, und der Mechanismus, der diese Fehler verursacht, kann entweder zu einer nicht-differenziellen oder einer differenziellen Fehlklassifikation führen. Ken Rothman unterscheidet diese wie folgt:
unterscheidet diese wie folgt:
„Bei einer Fehlklassifizierung der Exposition handelt es sich um eine nicht-differentielle Fehlklassifizierung, wenn sie nicht mit dem Auftreten oder Vorhandensein einer Krankheit zusammenhängt; wenn die Fehlklassifizierung der Exposition bei Personen mit und ohne Krankheit unterschiedlich ist, handelt es sich um eine differentielle Fehlklassifizierung. In ähnlicher Weise ist die Fehlklassifikation einer Krankheit nicht differenziell, wenn sie nicht mit der Exposition zusammenhängt; andernfalls ist sie differenziell.“
Nicht differenzielle Fehlklassifikation der Exposition
Nicht differenzielle Fehlklassifikation bedeutet, dass die Häufigkeit von Fehlern in den verglichenen Gruppen ungefähr gleich ist. Eine Fehlklassifizierung des Expositionsstatus ist ein größeres Problem als eine Fehlklassifizierung des Ergebnisses (wie auf Seite 6 erläutert), aber eine Studie kann durch eine Fehlklassifizierung entweder des Expositionsstatus oder des Ergebnisstatus oder beider verzerrt sein.
Eine nicht-differentielle Fehlklassifizierung einer dichotomen Exposition liegt vor, wenn Fehler bei der Klassifizierung unabhängig vom Ergebnis in gleichem Maße auftreten. Eine nicht-differentielle Fehlklassifikation der Exposition ist ein weitaus größeres Problem als eine differentielle Fehlklassifikation (bei der Fehler in einer der Studiengruppen häufiger auftreten). Die nachstehende Abbildung veranschaulicht eine hypothetische Studie, in der alle Probanden in Bezug auf das Ergebnis korrekt klassifiziert wurden, aber einige der exponierten Probanden in jeder Ergebnisgruppe fälschlicherweise als „nicht exponiert“ klassifiziert wurden.
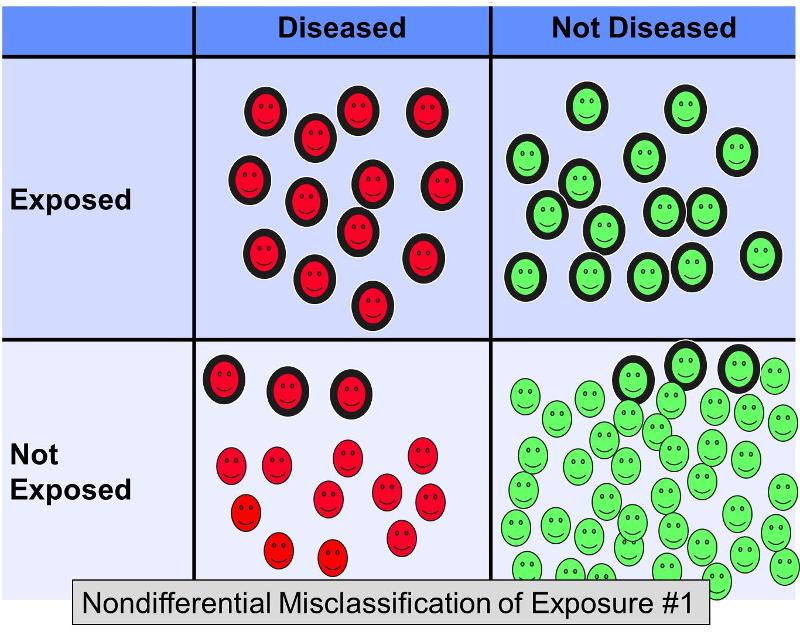
Angenommen, es wurde eine Fall-Kontroll-Studie durchgeführt, um den Zusammenhang zwischen einer fettreichen Ernährung und einer koronaren Herzkrankheit zu untersuchen. Probanden mit einer Herzerkrankung und Kontrollpersonen ohne Herzerkrankung könnten rekrutiert und gebeten werden, Fragebögen über ihre Ernährungsgewohnheiten auszufüllen, um sie als Personen mit fettreicher Ernährung zu kategorisieren. Es ist schwierig, den Fettgehalt in der Nahrung anhand von Fragebögen genau zu beurteilen, so dass es nicht überraschend wäre, wenn es bei der Klassifizierung der Exposition zu Fehlern käme. Es ist jedoch wahrscheinlich, dass in diesem Szenario die Fehleinstufung mehr oder weniger gleich häufig vorkommt, unabhängig vom späteren Krankheitsstatus. Eine nicht-differenzierte Fehlklassifizierung einer dichotomen Exposition führt immer zu einer Verzerrung in Richtung der Null. Mit anderen Worten, wenn es einen Zusammenhang gibt, wird dieser tendenziell minimiert, unabhängig davon, ob es sich um einen positiven oder negativen Zusammenhang handelt.
Die obige Abbildung zeigt ein Szenario, in dem der Krankheitsstatus korrekt klassifiziert wird, aber einige der exponierten Probanden fälschlicherweise als nicht exponiert klassifiziert werden. Dies würde zu einer Verzerrung in Richtung Null führen. Rothman führt ein hypothetisches Beispiel an, in dem das wahre Odds Ratio für den Zusammenhang zwischen fettreicher Ernährung und koronarer Herzkrankheit 5,0 beträgt, aber wenn etwa 20 % der exponierten Probanden in beiden Krankheitsgruppen fälschlicherweise als „nicht exponiert“ klassifiziert wurden, könnte die verzerrte Schätzung ein Odds Ratio von, sagen wir, 2,4 ergeben. Mit anderen Worten, sie führte zu einer Verzerrung in Richtung des Nullwertes.
Betrachten wir nun aber, was im gleichen Beispiel passieren würde, wenn 20 % der exponierten Probanden in beiden Ergebnisgruppen als „nicht exponiert“ UND 20 % der nicht exponierten Probanden in beiden Gruppen als „exponiert“ falsch klassifiziert würden – mit anderen Worten ein Szenario, das in etwa so aussehen würde:
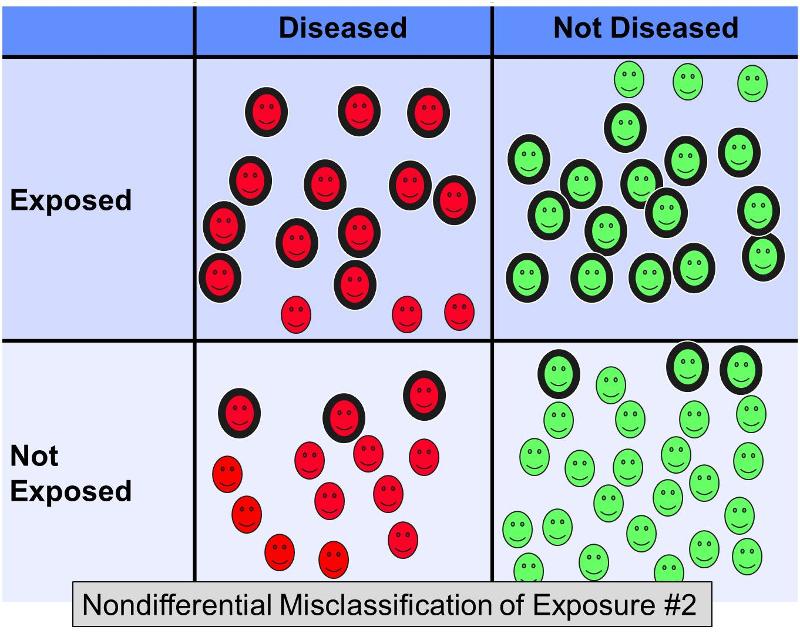
Diese zusätzliche nicht-differenzielle Fehlklassifikation würde zu einer noch stärkeren Verzerrung in Richtung der Null führen, was ein Odds Ratio von vielleicht 2,0 ergeben würde.
Bei mehreren Expositionskategorien, d.h. Wenn es mehrere Expositionskategorien gibt, d.h. wenn die Exposition nicht dichotom ist, kann eine nicht-differentielle Fehlklassifikation die Schätzung entweder in Richtung des Nullwertes oder davon weg verzerren, abhängig von den Kategorien, in die die Probanden falsch klassifiziert werden.
Mechanismen für nicht-differentielle Fehlklassifikation
Nicht-differentielle Fehlklassifikation kann auf verschiedene Weise auftreten. Aufzeichnungen können unvollständig sein, z. B. eine Krankenakte, in der sich keiner der Mitarbeiter des Gesundheitswesens daran erinnert, nach dem Tabakkonsum zu fragen. Es kann zu Fehlern bei der Aufzeichnung oder Interpretation von Informationen in den Aufzeichnungen kommen, oder es kann zu Fehlern bei der Zuordnung von Codes zu Krankheitsdiagnosen durch Büroangestellte kommen, die mit dem Krankenhausverlauf, der Diagnose und der Behandlung eines Patienten nicht vertraut sind. Probanden, die Fragebögen ausfüllen oder befragt werden, haben möglicherweise Schwierigkeiten, sich an frühere Expositionen zu erinnern. Wenn Schwierigkeiten bei der Erinnerung an frühere Expositionen in beiden zu vergleichenden Gruppen in gleichem Maße auftreten, liegt eine nicht-differentielle Fehlklassifikation vor, die zu einer Verzerrung in Richtung der Nullvariante führt. Wenn sich jedoch eine Ergebnisgruppe in einer Fall-Kontroll-Studie besser erinnert als die andere, dann liegt eine differentielle Fehlklassifikation vor, die als „Recall Bias“ bezeichnet wird. Der Recall Bias wird weiter unten unter differentielle Fehlklassifikation der Exposition beschrieben.
Zum Anfang zurückkehren | vorherige Seite | nächste Seite